dotData is a game-changing technology that uncovers the drivers that move your KPI. Harness the power of AI, ML, and Generative AI to uncover high-value business drivers from your most complex data — in minutes — empowering all your applications with actionable insights, whether in lending, financial services, manufacturing, just about anything.
Capture Signals Your
Models & Scorecards Miss
Uncover new critical signals for fraud, default, churn, yield losses, sales forecasts – or anything else – not captured by your models and scorecards.
Extract ALL Critical Signals
from Your Most Complex Data, AUTOMATICALLY

AI-Powered Data-Centric Discovery
Move from hypothesis-driven analysis to unbiased data-centric discovery. Leverage AI-powered insights—whether your goal is to understand what drives your KPIs or to build more accurate ML models.
Multi-Table, Multi-Modal Insights
Explore millions of data patterns—including numeric, categorical, time-series, and text data. Discover signals across all tables and columns to find deeper, high-value drivers.
10x More Signals, 10x Faster
Leverage dotData’s award-winning AI technology to empower your analytics and data science teams to automatically traverse all your unexplored data tables at 10x the speed.
Unlock Maximum Value from Multi-Source,
Multi-Table, and Multi-Modal Data
dotData uncovers multi-modal signals by exploring multiple columns across diverse tables and sources. It discovers key drivers to power data applications including business intelligence, analytics, machine learning, generative AI, and more.

dotData Product Suite:
AI-Powered Insights Empower All Data Applications
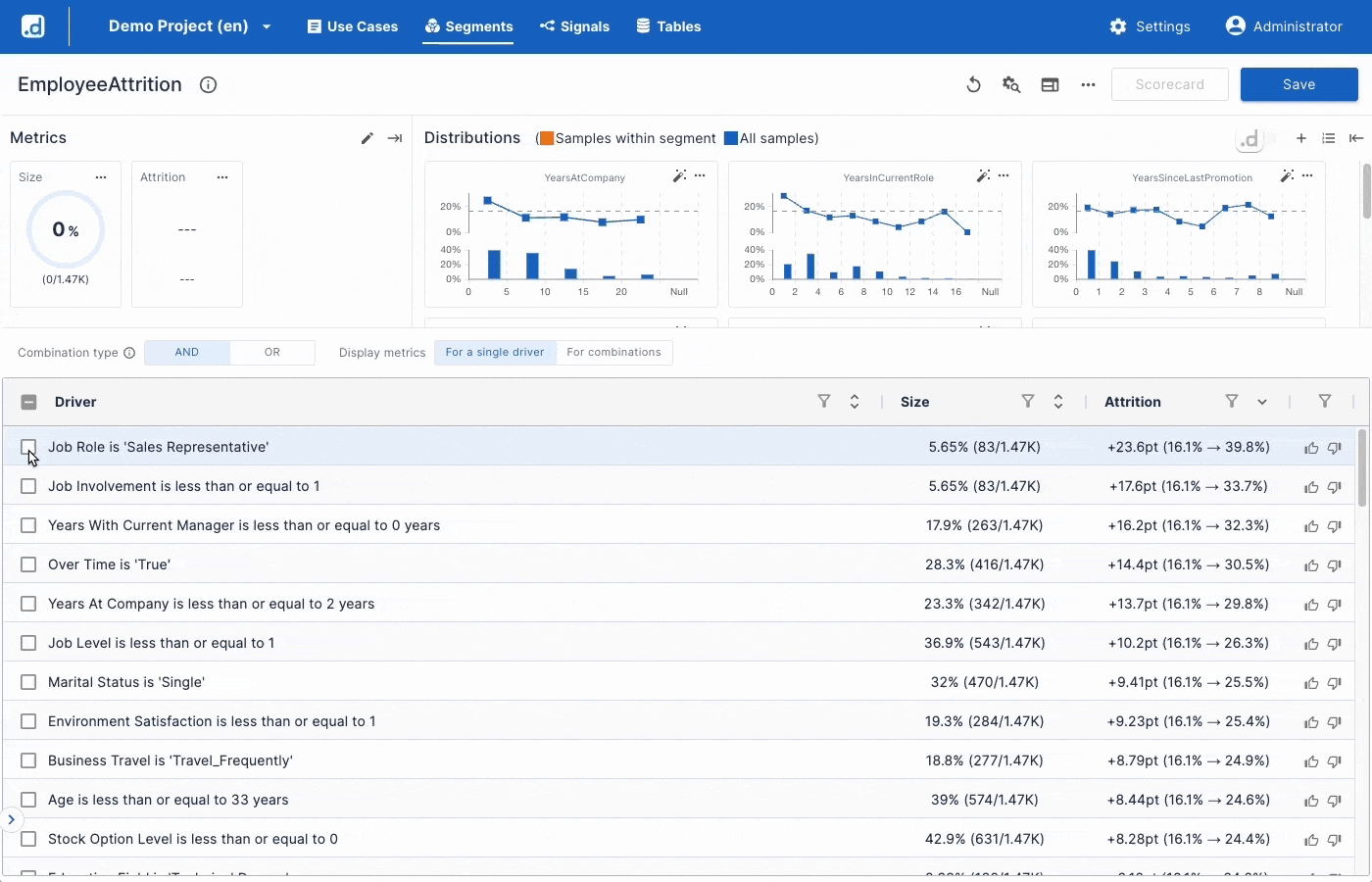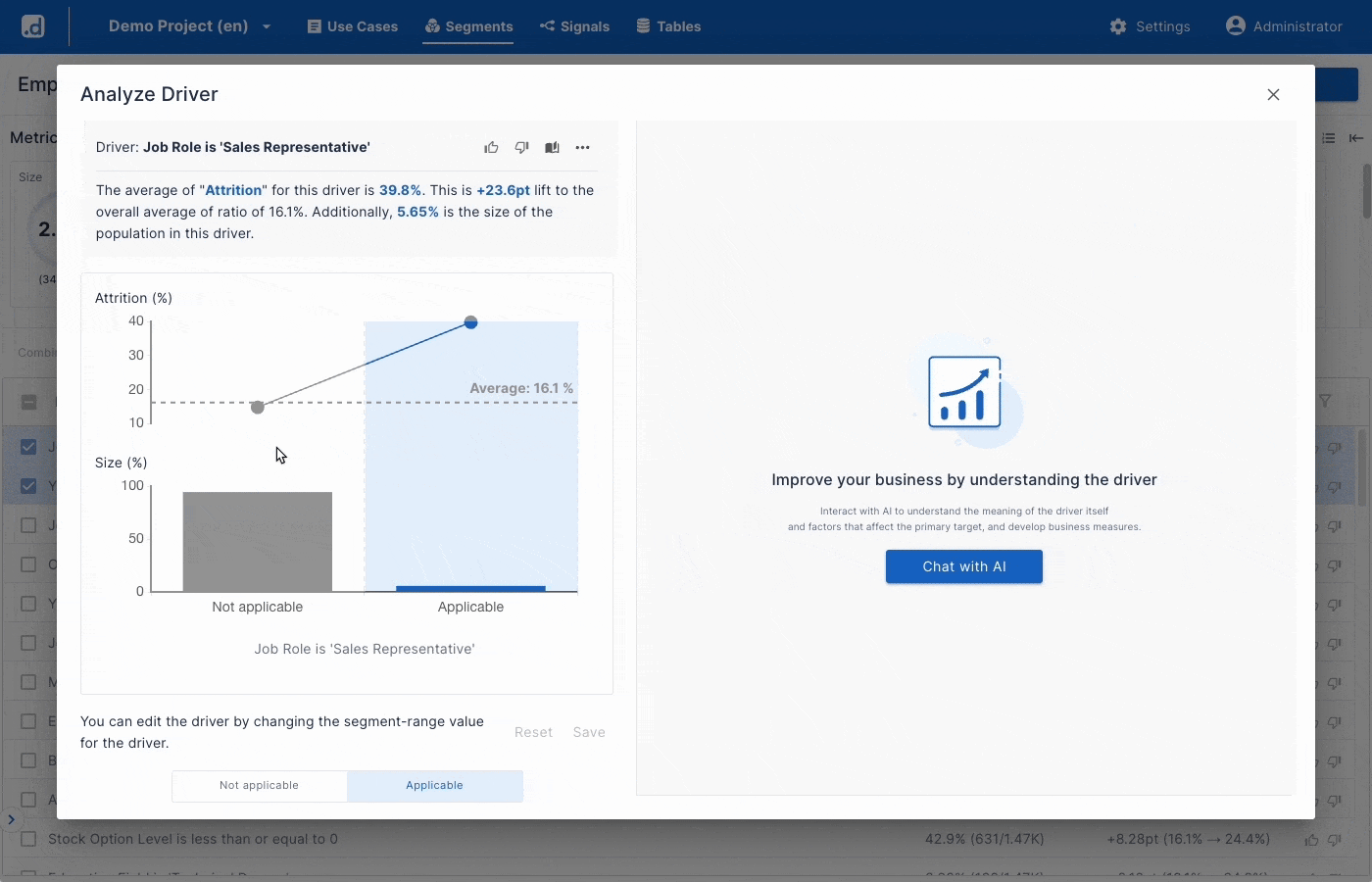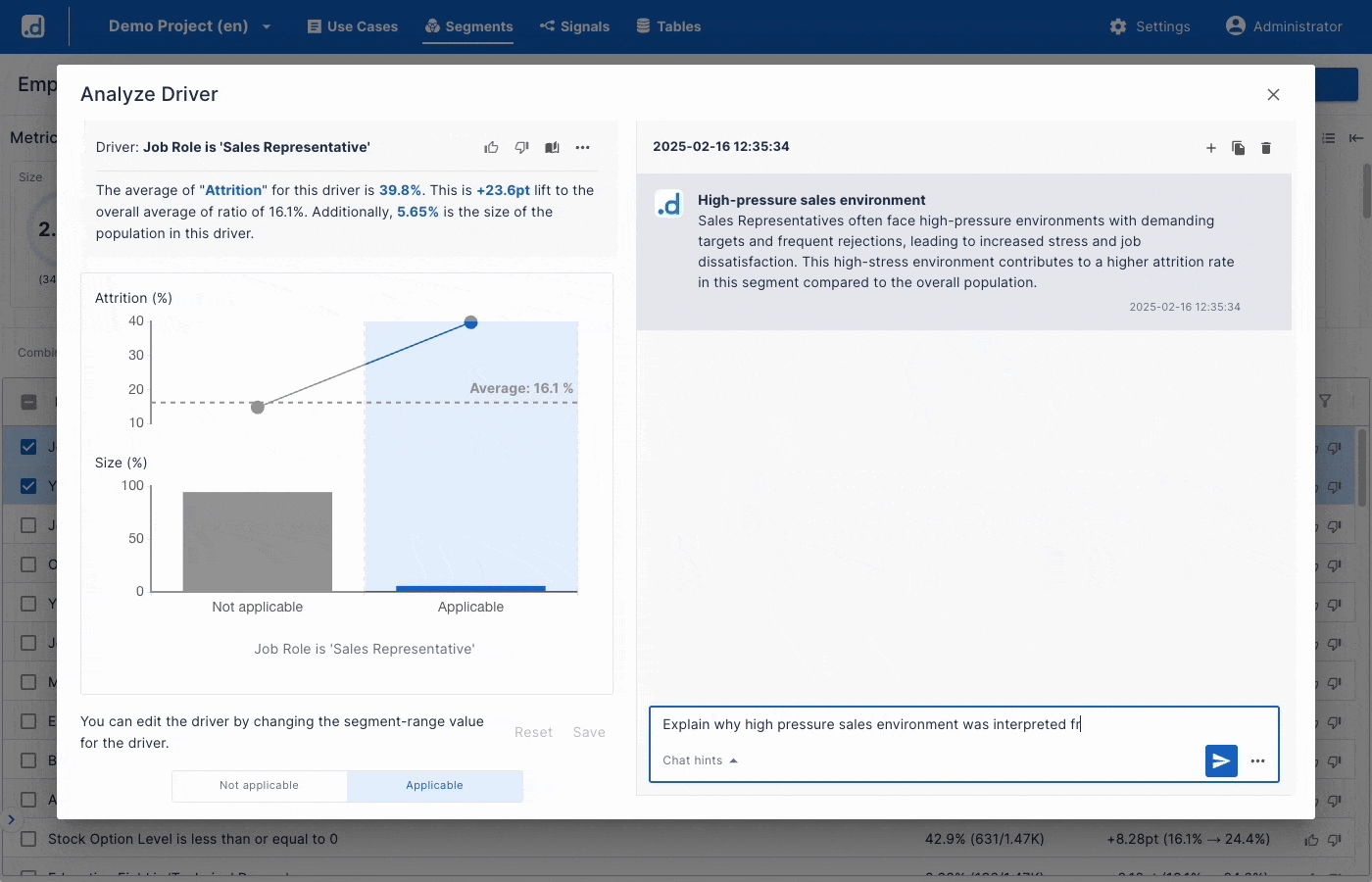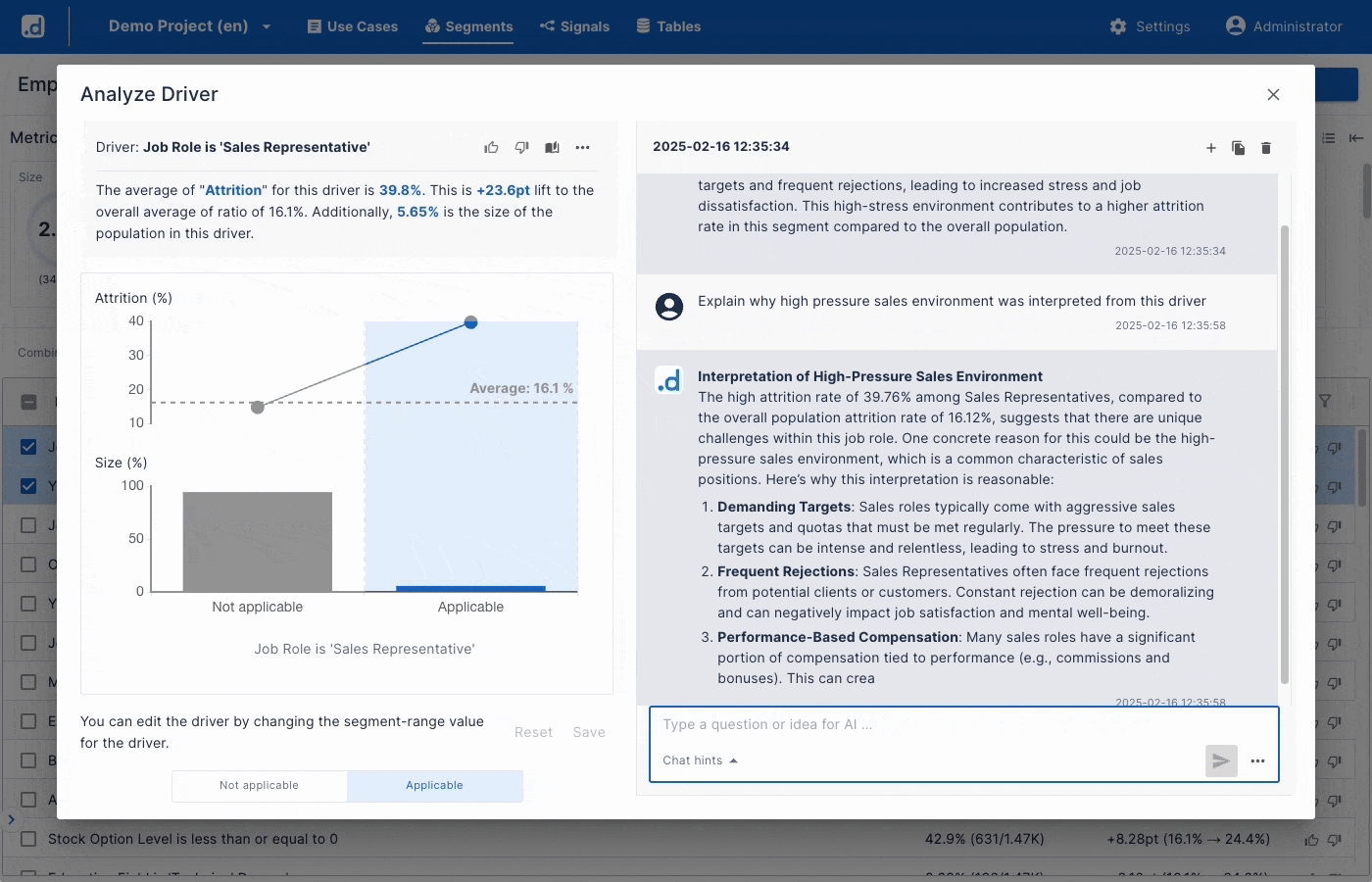
Uncover What Drives Your KPIs
- Explores Millions of Signals
Automatically uncover what drives your KPIs. Turn unexplored data into high-value insights in minutes. - Ideate Actionable Hypotheses with GenAI
Use GenAI to convert statistical signals into business hypotheses. Dive deeper to boost KPIs. - One Click Powerful Scorecards
Score your data in one click using high-impact drivers. Identify exact records to focus on and improve your KPIs.
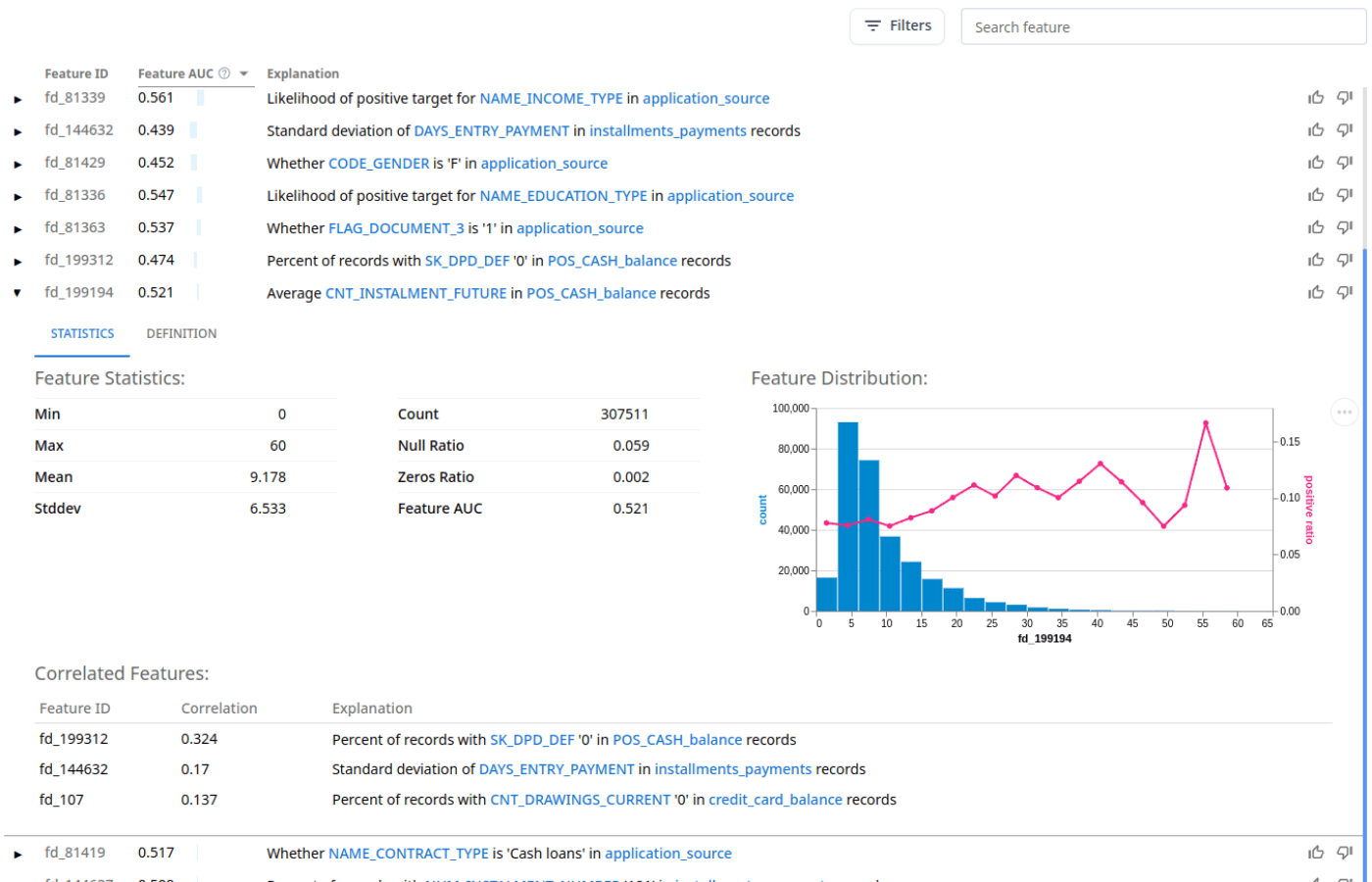
Build More Accurate Models
- Data-Centric & LLM-Powered
Programmatically identify millions of feature patterns. Accelerate feature ideation with LLM. - More Accurate Models
Incorporate unexplored data into your feature space. Boost your ML model accuracy – guaranteed. - Multi-Table and Time-Series
Extract key drivers by combining all tables and columns. Build features across multiple time windows.
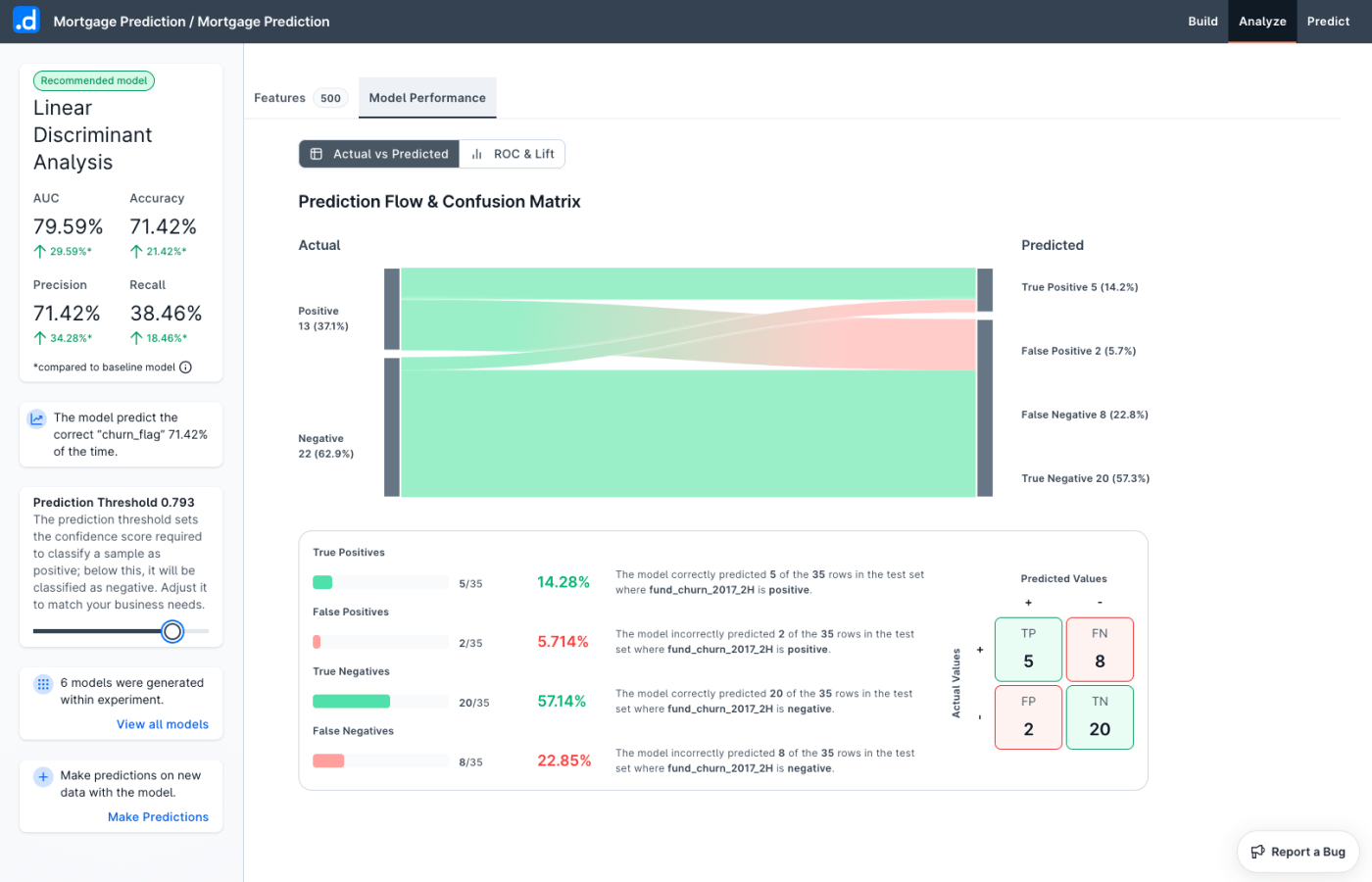
Empower Citizen Data Scientists
- No-Code Predictive AI
Enable data analytics teams to build predictive models without coding or specialized knowledge. - Automated Feature Engineering
Integrate automated feature engineering with AutoML – from data to models in minutes. - Explainable AI
Produce explainable features and models to make your AI more actionable.

Orchestrate Models, Features, and Data
- Self-Service Deployment
Empower analytics teams to deploy and operate data, feature, and model pipelines without IT involvement. - Model and Feature Drift
Monitor model accuracy and feature distributions over time to detect drift as your data evolves. - Source Data Diagnosis
Identify the tables and columns responsible for model and feature drift by tracing problems back to the source data.
Who dotData Empowers
For BI and Analytics Teams
- Discover Signals Hidden in Unanalyzed Data.
- Data-Centric Discovery of KPI Drivers.
- Derive 10x more insights, 10x faster.
For Data Science Teams
- Boost Model Accuracy.
- Jump-Start Data & Feature Discovery.
- Make Your Feature Space Data-Centric and Programmatic.
Featured Industry






News
Press Release
dotData Launches dotData TextSense 1.3, Delivering Ultra-Low-Cost, Highly Secure Enterprise Text Labeling
Press Release
dotData Successfully Completes SOC 2 Type II Audit for Fourth Consecutive Year
Press Release
dotData Named One of the Most Influential Companies in Subprime Auto Finance by SubPrime Auto Finance News
Press Release
dotData Expands AI Accessibility with Self‑Managed Deployment and Next‑Gen Text Analytics Capabilities
Press Release
dotData Announces dotData Insight’s Native Support for Databricks and Snowflake on Microsoft Azure