
Building a Modern Auto Credit Decisioning Engine in 2026
- Industry Use Cases
Due to rapidly changing borrower behavior, economic uncertainty, and technological advances, traditional lending underwriting models are increasingly struggling to distinguish low-risk borrowers from high-risk ones. Inflation has also affected the affordability of Prime borrowers, creating a false sense of security that a generic FICO score does not capture. Simultaneously, the democratization of generative AI has equipped fraudsters with industrial-scale tools to manufacture synthetic identities, resulting in a massive increase in synthetic fraud attempts and exposing lenders to billions in potential losses.
For Chief Risk Officers (CROs), Chief Lending Officers (CLOs), and Heads of Data Science, it’s no longer enough to focus on digital transformation or improving efficiency. The new reality is that the lag between market shifts, like sudden drops in Electric Vehicle Values, and a lender’s ability to respond can have immediate implications for profitability. Traditional credit decisioning systems that rely on manual model updates and occasional policy or pricing adjustments are causing immediate problems.
The financial implications of inaction are severe. Lenders that rely on automation can expect to reduce operational expenses by up to 40% through efficiency gains.
As we enter 2026, the traditional, widely accepted use of credit scores in making lending decisions is under pressure. The heavy reliance on credit scores, such as FICO, based on historical repayment performance, makes them lagging indicators that are insufficient to predict default behavior in high-inflation, high-interest economic conditions, and uncertain job markets. The core assumption of traditional scoring is that past behavior predicts future performance. Still, this assumption breaks down when we consider the economic pressures that are changing household liquidity faster than consumer credit reporting cycles.
A borrower who had a 740 FICO score in 2024, but was under financial strain, may have maxed out revolving credit lines during 2025 to stay ahead of mortgage and auto loan payments. Inflation has eroded buying power and shifted disposable income previously used to service auto debt toward necessities. Inflation-adjusted balances for Prime borrowers have declined, suggesting a weakening in purchasing power rather than a healthy expansion in credit use.
In fact, delinquency rates have exceeded pre-pandemic levels, and even among prime and super-prime borrowers, they have been driven largely by rising loan balances and higher interest rates.
The market is also seeing a more complex risk picture. While household balance sheets appear healthy, the same is not true among lower-income and younger demographics, and is increasingly threatening the higher end of the credit spectrum:
Lenders that rely solely on bureau data are like drivers who rely solely on the rearview mirror. Lenders must combine trend data with permission-based liquidity data from checking accounts and utility payment histories to determine a borrower’s ability to pay today, not their historical ability to pay.
A new pressure point on the auto lending industry is the industrialization of fraud. Synthetic identity fraud, in which a real Social Security number is combined with false information, has shifted from hackers to organized crime rings. In fact, auto lenders faced $2 billion in losses in the first half of 2024 alone.
Generative AI has acted as a force multiplier for fraud rings. The World Economic Forum (WEF) warns that generative AI now enables a single threat actor to execute up to 90% of an attack with minimal human intervention. As early as the summer of 2024, the Global Association of Risk Professionals warned that fraudsters using AI could create “deepfake” documents that pass “know your customer” checks.
Synthetic identities created with AI are not used for immediate attacks. Instead, synthetic IDs are nurtured over months to build a positive credit profile. Fraudsters open small tradelines, stay current on payments, and work towards a 700+ credit score, with the ultimate goal of executing a “bust-out.” Typically done within a 48-hour window, fraudsters apply for multiple high-value loans across multiple lenders. Fraudsters rely on the simple fact that credit bureau data updates are not real-time, giving each financial institution a narrow view into what seems to be a “prime” borrower with low credit utilization. Once the loan is approved, the fraudster withdraws maximum funds, takes delivery of a vehicle, and disappears.
For auto lenders, this manifests in specific, high-loss patterns:
A decisioning engine that assumes document validity is fundamentally broken. Systems must integrate forensic analysis and behavioral biometrics before the credit decision is even executed.
Lenders are now facing a vehicle value problem on two fronts. Used car values, which peaked during the pandemic, have now normalized. In addition, an oversupply of luxury vehicles and the expiration of EV incentives have exacerbated the problem.
The value of a vehicle impacts the Loss Given Default (LGD). Lenders who rely solely on book value, without accounting for market volatility, as seen in recent auction data, risk approving loans with Loan-to-Value (LTV) ratios that are underwater from the start.
Electric Vehicles (EVs) present a unique challenge. Used EV prices are forecast to decline by $1,500 to $2,500 in 2026 as off-lease returns enter the used-car market. A lender using a standard depreciation curve for a Tesla Model 3 or Ford Mach-E will underestimate their LGD. If the collateral loses value faster than the loan amortizes, the loss severity increases.
In 2026, lenders must account for a vehicle’s future value at the time a potential default may occur, rather than its current value, requiring analysis of recent auction data to better model vehicle depreciation in their decision-making.
For greater flexibility, lenders must adapt their Loan Origination Systems (LOS) with additional layers of automation that enable deeper data analysis, faster risk model updates, and integration of third-party data without impacting core functionality.

A robust auto decisioning architecture in 2026 consists of five distinct layers:
A decision engine is only as intelligent as the data it consumes. The 2026 engine is defined by its connectivity. It is not an island; it is a hub that provides a unified view of the borrower’s creditworthiness.
Table 1: The Modern Data Ecosystem for Auto Lending
| Data Category | Examples | Strategic Value in 2026 |
|---|---|---|
| Traditional Credit | Experian, TransUnion, Equifax | Baseline history. Trended Data is now standard, revealing if a borrower is transacting (paying in full) or revolving (paying minimums). |
| Alternative Credit | Telecom, Utility, Rent (Urgent, etc.) | Scoring “thin file” and “invisible” borrowers who lack trade lines but have payment discipline. |
| Cash Flow / Banking | Plaid, Finicity, MX | Real-time income verification and Residual Income analysis. Essential for gig-economy workers. |
| Fraud & Identity | SentiLink, Point Predictive, Socure | Detecting synthetic IDs, bust-out patterns, and device inconsistencies (e.g., mismatched IP geolocation). |
| Asset Valuation | Black Book, Kelley Blue Book, J.D. Power | Real-time VIN-level collateral valuation is essential for accurate LTV and LGD modeling in a depreciating market. |
| Document Forensics | Ocrolus, Inscribe | Detecting AI-generated forgeries in pay stubs and bank statements via pixel-level analysis. |
A critical distinction for Data Science leaders in 2026 is between storing features and discovering them.
Products like Databricks provide the infrastructure and are critical in powering the online-offline skew problem. With modern platforms, discovered signals (known in data science terms as “features”) are computed during model training and are mathematically identical to those used in live lending. Fundamentally, however, systems like Databricks are ideal for serving features rather than creating them.
Architecting features is where you can discover value. Platforms like dotData Feature Factory solve the “cold start” problem. A feature store can store monthly_average_balance, but it cannot look at raw transaction logs and invent the feature ratio_of_weekend_spending_to_weekday_spending as a predictor of risk.
Feature Factory is built around multi-modal discovery. By ingesting multiple related raw data sources, Feature Factory can generate and evaluate thousands of potential signals in just hours, rather than days or weeks. Through automation, lenders can analyze demographic data, transaction histories, bureau data, and more in a fraction of the time it takes to perform the analysis manually.
In 2025, loan origination costs continued to rise, driven by compliance overhead and labor costs. Manual underwriting is constrained by the bottleneck of underwriters physically reviewing PDF pay stubs and comparing them to values in specific LOS fields.
Manual loan origination is unscalable. Manual processing costs rise with volume, and manual reviews are susceptible to “reviewer fatigue,” leading to higher error rates as credit application volumes increase. Manual workflows are also influenced by human behavior, as two underwriters may make different decisions on the same loan based on subjective judgments. Automation can reduce operational costs by up to 40% while significantly shortening production timelines.
A modern engine segments applications into three unique categories based on risk and complexity to optimize the use of human resources:

As artificial intelligence has become pervasive, many data science teams are tempted by Deep Learning, also known as Neural Networks. While deep learning systems can model complex nonlinear relationships, they can also create a compliance headache.
Deep Neural Networks (DNNs) transform inputs into high-dimensional abstractions through multiple hidden layers. When a DNN denies a loan, it’s effectively saying, “because the math says so.” Still, it cannot easily isolate the unique conditions of any single variable, such as the debt-to-income ratio. The inability of a DNN to identify the variables that influenced a decision in a way that is easy for humans to interpret makes them problematic for lending.
While tools such as Shapley Additive Explanations (SHAP) and Local Interpretable Model-agnostic Explanations (LIME) have increasingly been adopted in the lending industry to provide transparency into DNN decision-making, they also present challenges. LIME can provide different explanations for the same data point. While SHAP is the preferred method, both are approximations of the black-box model and do not fully capture its logic, leaving lenders vulnerable to being cited for providing ‘inaccurate’ reasons for denials.
The superior architectural choice for 2026 is to move the “intelligence” from the model to the features.
Instead of feeding raw pixels or unstructured data into a black box, lenders should use Advanced Feature Engineering to create highly predictive, yet human-understandable inputs. Compare these two approaches:
An EBM model can provide clear, transparent, and traceable reasons for a loan denial, such as “too many NSF events.” At the same time, EBM models maintain predictive power comparable to that of neural networks because they rely on features to capture nonlinear relationships in the data.
Transparent, explainable signals are at the core of dotData Feature Factory: discovering millions of candidate features from complex relational data, evaluating each, and surfacing the most impactful ones as explicit, explainable logic.
Feature Factory automates the creation of interpretable features like “sum of deposits where description contains ‘payroll’ in the last 3 months.” Because Feature Factory can capture these signals as features, data scientists can achieve performance comparable to deep learning while maintaining the transparency and auditability required for compliance. The data scientists can “curate” these features, selecting the top 20-50 most predictive and compliant ones for the production model, ensuring alignment with Fair Lending laws.
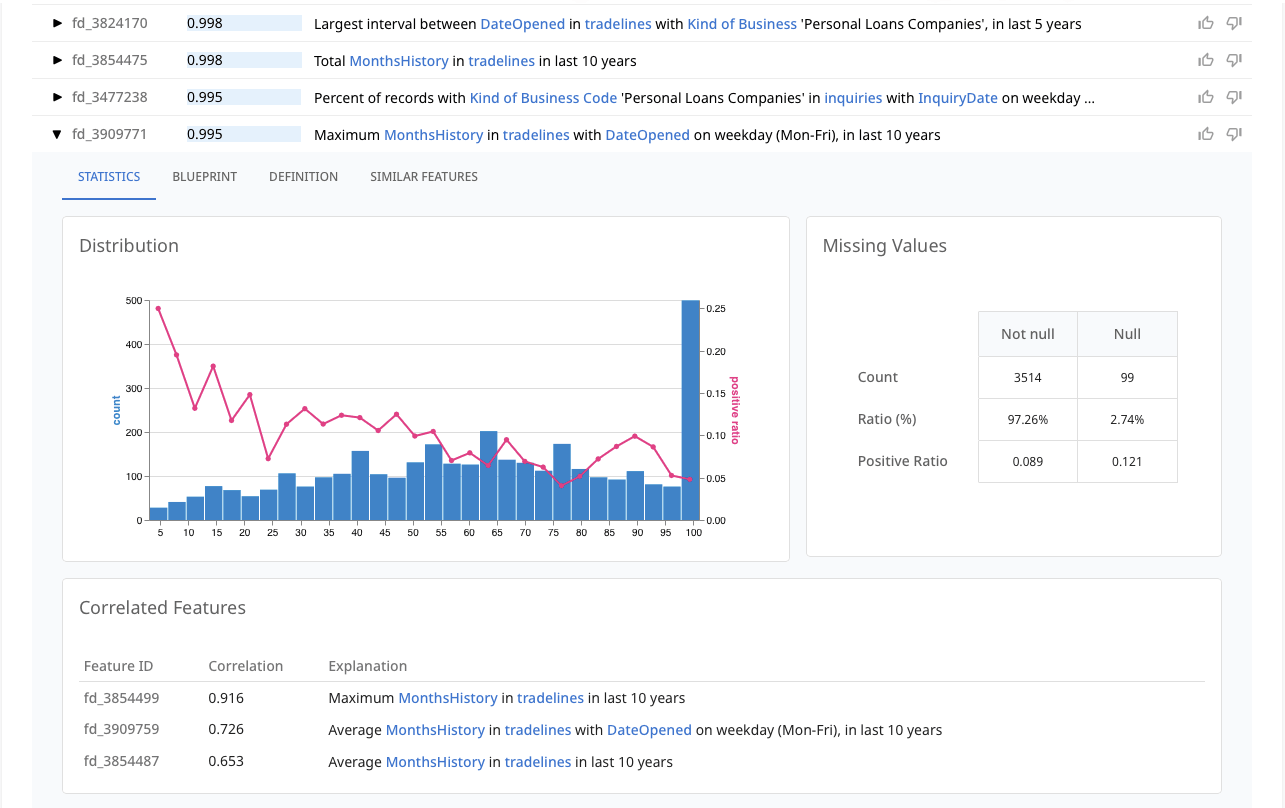
While Feature Factory empowers the data scientist, the Business Executive (CRO/CLO) needs visibility into the data. This is the role of dotData Insight.
A decision engine is not a “set it and forget it” system. Market conditions change weekly. The CRO needs a dashboard that not only shows what happened (e.g., “Delinquency up 0.5%”) but also explains why.
dotData Insight enables line-of-business users to visualize delinquency drivers in an easy-to-understand format. For example, it might discover a combination of drivers, known as a micro-segment, that indicates a high propensity for high roll rates. Signals like “Borrowers with loans of $30K+ AND payment date on the 15th AND in Region X have a 21% higher roll rate.” This type of functionality allows for two critical benefits:
Transitioning to a modern credit decisioning model that maximizes the use of automation can be capital-intensive, but it offers compelling returns:
Lenders that still employ largely manual review processes, static scorecards, and legacy systems are more likely to absorb higher operating costs, increased losses, and win fewer deals. Competitors who adopt a modern architecture, on the other hand, will not only survive current turbulent times, but are more likely to emerge leaner, faster, and with a more profitable portfolio.


