
Lending Fraudsters Are Hiding in Your Portfolio, AI Can Spot Them
- Industry Use Cases
In late 2025, the collapse of Tricolor Holdings, a major provider of subprime auto loans, sent a shockwave through the lending industry. On the surface, it appeared to be another casualty of a tightening market. But a closer look revealed a more ominous sign. According to reports from Kelley Blue Book, the company’s bankruptcy filing came shortly after revelations that the U.S. Justice Department was investigating allegations of fraud. Fifth Third Bancorp, one of Tricolor’s key warehouse lenders, confirmed it had discovered “alleged external fraudulent activity” tied to loan balances of $200 million.

The Tricolor Holdings nightmare was a warning shot for the lending industry. The event served as a reminder of the risks hidden within the loan portfolios of all lending organizations. Fraud is often a significant, if underestimated, contributor to costly losses. The fallout was also no longer isolated to the subprime lending, with major institutions such as J.P. Morgan Chase and Barclays bracing for hundreds of millions of dollars in potential losses.
The Tricolor story is a cautionary tale about a critical vulnerability: the misclassification of risk.
The nature of lending fraud has evolved. It’s no longer just about stolen identities, as schemes are becoming more sophisticated, data-driven, and designed from the outset to evade traditional screening methods. To combat the next-generation threats that are becoming increasingly pervasive, lenders need to move beyond basic rule-based systems and credit scores to a proactive approach that can unearth subtle, interconnected patterns buried within data already available to most lenders and credit unions.
In this post, we will explore the top fraud trends and demonstrate how AI-powered analytics provides a powerful new line of defense in the auto lending landscape.
The financial impact of auto lending fraud is staggering and growing at an alarming rate. According to research from TransUnion, lender exposure to synthetic identity fraud alone increased to $3.3 billion in 2024, with auto lenders suffering the most significant exposure at $2.1 billion— a 250% increase since 2020. The Federal Trade Commission paints an even bleaker picture, reporting that as many as 21,446 auto loan or lease identity theft reports were filed in the first quarter of 2025, a staggering 75% increase from the previous year.
The surge in fraud is driven by a different type of activity, which is typically not on the radar of auto lenders. As a result, fraud in auto loans was significantly higher than in other loan types. The dominance of first-party fraud, where the applicant or a complicit dealership intentionally misrepresents information, is a significant shift.
In fact, first-party fraud now accounts for an astonishing 69% of the industry’s total risk of fraud, fundamentally changing the detection challenge. Legacy systems are designed to defend against third-party fraud, where a criminal uses a stolen identity; however, traditional techniques are often ill-equipped to handle situations where the applicant is the fraudster, using their real name but fabricating the details required to get approved.
| Metric | Key Statistic | Source |
|---|---|---|
| Fraud Reports (Q1 2025) | $21,446 Billion (a 75% increase) | FTC |
| Synthetic Fraud Exposure (2024) | $3.3 Billion | TransUnion |
| Synthetic Fraud in Auto Lending | $2.1B (a 250% increase over 2020) | TransUnion |
| Income/Employment Fraud | Accounts for 43-45% of total fraud losses | DigitalDealer |
| Intentional Default (EPD) | ~70% of early payment defaults show signs of application fraud | DigitalDealer |
With increasing fraud incidence rates, lenders must understand the new playbook of fraudsters and credit washers to effectively defend themselves. In today’s most damaging schemes, fraudsters exploit the weaknesses endemic in traditional underwriting and fraud detection systems.
Synthetic identity fraud is not identity theft but the fabrication of identity. Fraudsters create a new, fictitious identity by combining real and fake information. For example, they use a real Social Security number belonging to a minor or an older adult (who is unlikely to monitor their credit) and combine it with a fabricated name, address, and date of birth to create a new identity.

The actual danger of this scheme lies in the “nurturing” process. Over months or even years, the fraudster patiently builds a seemingly legitimate credit history for this “Frankenstein” identity. They may open a low-limit credit card, make small purchases, and pay the bill on time, gradually establishing a positive credit file. High-risk behaviors can be masked behind seemingly firm credit profiles, which might have trouble paying on time later. This makes it harder to ensure each person is reliably represented in the auto lending marketplace.
Synthetic fraud is devastatingly effective because it bypasses a fundamental pillar of traditional fraud detection: victim reporting. With standard identity theft, the real victim eventually notices suspicious activity and reports it, creating a clear red flag for lenders. With a synthetic identity, no single victim can sound the alarm. To a lender’s system, the application appears to be from a desirable “new-to-credit” or “thin-file” customer. The scale of the problem emerges as a growing concern, with estimates suggesting that US lender exposure to synthetic identities across auto, credit card, and unsecured personal loans totaled $3.3 billion in potential losses at the end of 2024.
For decades, lenders have viewed a first-payment default (FPD) as a sign of a high-risk borrower who overestimated their ability to pay—a credit risk. The FPD default as a “high risk” predictor is dangerously outdated, since a significant portion of today’s FPDs should be reclassified as a calculated fraud scheme. The applicant has zero intention of ever making a loan payment; their sole objective is to secure the asset (the vehicle) and disappear.
A skip is the worst possible outcome for a lender: a total asset loss with no legitimate party to pursue for recovery. The vulnerability in this case is operational. In a non-fraudulent early default scenario, the loan is usually routed to the collections department and written off as a loss. The fraud team is never alerted to potential data misrepresentation at the time of origination. The blind spot created ensures that the lender never learns from the event and cannot prevent future similar situations. The data confirms this disconnect: up to 70% of early payment defaults—loans that default within the first six months—contain clear evidence of fraud or material misrepresentation on the initial application.
Misrepresentation of income and employment has evolved from what was once merely “fudging” numbers into the single most significant driver of fraud losses in the auto lending industry, accounting for up to 45% of fraud exposure.

The open availability of digital technology has made forging pixel-perfect pay stubs and bank statements simple and effective enough to fool most traditional review processes. The real threat, however, is from new, more sophisticated “Fraud as a Service” schemes that have become pervasive. Criminal organizations can offer fake employment histories backed by shell company websites and active telephone numbers to bypass verification calls. The organized industrialization of fraud has rendered traditional screening processes ineffective, with pay stubs often being forged or generated online with falsified information. The challenge of trusting a historically reliable verification form is forcing lenders to impose stricter rules on legitimate borrowers, creating friction and slowing the entire funding process.
A straw borrower scheme exploits the very logic of credit-based lending. In this scenario, a person with an excellent credit history is recruited to apply for an auto loan on behalf of someone unqualified. The application looks pristine: the credit score is high, the income is verifiable, and the debt-to-income ratio is well within guidelines.
Straw-borrower fraud is complicated because it exploits a lender’s reliance on proven credit scoring methodologies. A traditional underwriting model, designed to reward applicants with firm credit profiles, will likely view a straw-borrower application as low-risk and may even expedite its approval. The fraud is not in the data points but in the application’s hidden intent. Detecting straw borrowers requires looking beyond the primary application data to find subtle, contextual clues that traditional models often ignore, such as a considerable distance between the applicant’s home address and the dealership, or strange patterns in how co-borrowers are added or removed from subsequent applications.
What’s most concerning is that this behavior is increasingly prevalent among consumers in lower-risk credit tiers, where lenders typically expect better credit performance. To stay ahead, lenders must integrate fraud-specific attributes and verification tools that can detect these anomalies.
The rise of these sophisticated auto loan fraud schemes has exposed the fundamental flaws in the lending industry’s legacy defense systems.
For years, many lenders’ primary line of defense has been the static rules engine, a system based on simple “if-then” logic. For example, a rule might be: IF credit_score < 620 AND time_on_job < 6 months, THEN flag_for_review. While straightforward, this approach has several critical weaknesses.
First, it is inherently reactive. A rule is only created after a new fraud pattern has been identified and caused financial losses. Fraudsters are adept at probing systems, learning the rules, and then engineering their applications to bypass them. This creates a perpetual and unwinnable arms race where the lender is always one step behind the criminal.
Second, rule-based systems are prone to errors and generate many false positives. Overly strict rules often flag legitimate customers, creating unnecessary friction in the lending process and wasting the valuable time of fraud investigators who must manually review these flagged files. Finally, maintaining a complex rule set requires constant manual updates by domain experts, making the system expensive and slow to adapt.
The most significant failure of traditional models is their narrow view of the available data. Most underwriting and fraud systems rely heavily on a limited set of information, primarily the consumer credit bureau report and the data provided on the application form. Traditional models fail to incorporate and find patterns in the vast universe of richer, alternative datasets that provide crucial context.
Fraud is often revealed not by a single “bad” data point, but by the incongruous context surrounding otherwise “good” data. A straw borrower looking for auto financing options may have an excellent credit score, but they live 200 miles from the dealership or show disproportionate income. These contextual signals are where the true story of risk lies, but legacy systems are architecturally blind to them and are designed to validate individual data points, rather than analyzing the holistic narrative the combination of all available data reveals.
To win the evolving fraud battle, lenders must shift their approach to fraud detection from looking for single, predefined red flags to identifying hundreds, often thousands, of small, interconnected signals across all available data. Combining the subtle clues hidden in data that all lenders already have access to can help an accurate picture of auto lending fraud emerge.
A traditional fraud detection system is akin to a security guard, armed with a simple checklist, looking for known violations one at a time. An AI-powered system is like a seasoned detective—an investigator with a team of skilled criminal scientists, noticing small but significant inconsistencies in a suspect’s story, behavior, and available evidence. No single clue is damning on its own, but the complete picture paints a clear state of deception.
Sifting through seemingly small clues is precisely the kind of “detective work” that AI-driven analytics platforms, such as dotData Feature Factory and dotData Insight, are designed to automate on a massive scale. By systematically exploring all possible connections and patterns within complex datasets, these platforms can spot the combinations of clues that signal fraudulent intent, making this powerful capability accessible to highly technical data science teams and business-focused analysts.
Lending data science teams face the challenge of manually engineering features designed for fraud detection. Preparing the data, creating predictive variables, and testing them is time-consuming, needs deep domain expertise, and often yields diminishing returns as the best, most obvious features are identified. This is where manual feature engineering breaks down and automation becomes critical.
dotData Feature Factory is designed to automate this entire workflow, transforming the data scientist’s role from a manual data preparer to a strategic modeler.
The workflow is designed for speed and power:
Business leaders, underwriting managers, and risk analysts must understand the drivers of fraud to make informed strategic policy and operational decisions. However, they cannot afford to wait weeks or months for long data science cycles to deliver reports. They need clear, actionable answers now.
dotData Insight is a point-and-click platform that utilizes the same powerful AI engine as dotData Feature Factory, but is specifically designed for business and BI users. It closes the gap between a business question and a data-driven answer.
The approach is intuitive and business-focused:
The fight against loan application fraud has become a data-driven arms race. Fraudsters are leveraging technology to forge documents, fabricate identities, and create synthetic histories at an industrial scale. Relying on outdated, reactive methods is no longer viable; it’s a recipe for significant financial loss.
An AI-powered approach offers a fundamentally new and more effective line of defense. It shifts the paradigm from searching for known red flags to discovering the complex, hidden risk patterns across an organization’s data.
This provides a powerful dual benefit:
Don’t wait for a major fraud event to expose the gaps in your defenses. It’s time to unlock the intelligence hidden in your data. Schedule a demo with dotData to see how to build a more resilient and intelligent lending operation.
Synthetic identity fraud involves creating a new, fake identity by combining factual information (like a stolen Social Security number from a minor) with fabricated details (like a phony name and address). It is challenging to detect because, unlike traditional identity theft, no single victim can report the crime. To a lender’s systems, the synthetic identity often appears as a legitimate “new-to-credit” applicant, bypassing many standard identity verification checks.
Traditional rule-based systems are reactive; they utilize static “if-then” rules to identify known fraud patterns. This means they are always a step behind fraudsters, who constantly adapt their methods. AI-driven fraud detection is proactive. It analyzes all available data to discover thousands of subtle, interconnected patterns—even novel ones—that indicate fraudulent intent. It’s like having a seasoned investigator who can see the whole picture, not just a guard with a simple checklist.
dotData Feature Factory acts as a massive accelerator for data science teams. Much of any modeling project is spent on manual data preparation and feature engineering. dotData Feature Factory automates this entire process. It allows data scientists to connect raw data and automatically discover millions of potential features, ranking the most predictive ones. This frees them from tedious manual labor, allowing them to focus on higher-value tasks, such as model strategy, validation, and deployment, ultimately helping them build more accurate models much faster.
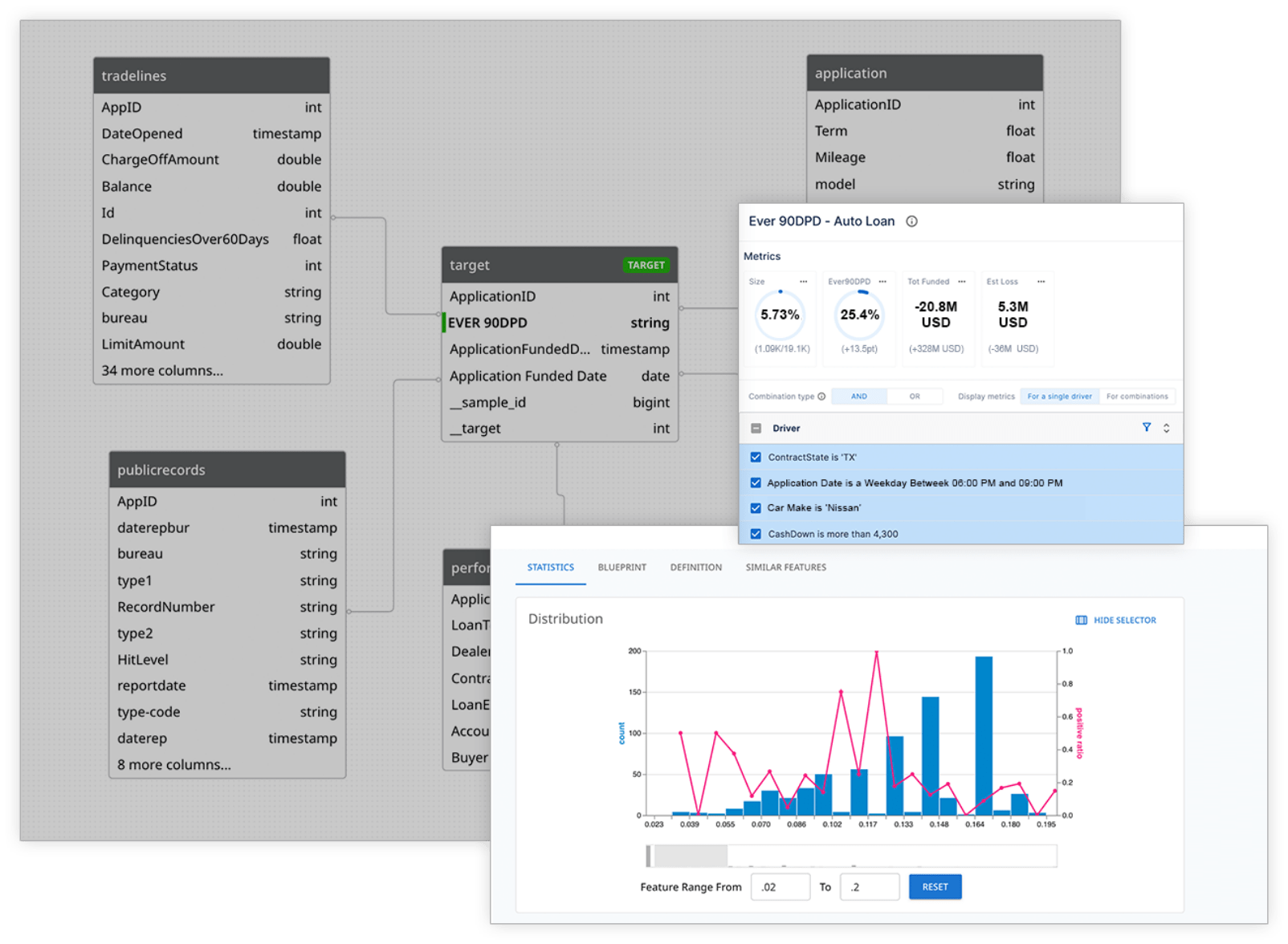
dotData Insight is a no-code platform designed for business users. An analyst can simply define a business KPI, like “Likelihood of Fraud. ” The platform’s AI engine will automatically discover the key Business Drivers influencing that KPI from the data. Users can then interactively explore these drivers, combine them to find high-risk segments, and even create scorecards to apply this logic to new applications—all without writing any code.
A micro-segment is a small but highly concentrated group of records identified by combining multiple business drivers. For example, an individual driver might show a 10% lift in fraud risk. But when you combine three or four such drivers, you might find a tiny segment (e.g., 0.5% of applicants) with an 800% higher fraud rate. This is important because it allows lenders to take targeted action—such as requiring extra verification or declining an application—on a tiny, high-risk population without creating unnecessary friction for most legitimate customers.


