The Invisible Thief: Synthetic Identity Fraud in Auto Lending
- Industry Use Cases
The “South Beach Bust Out Syndicate” was an organized fraud ring broken up by federal investigators in Florida. The syndicate used sophisticated synthetic identity fraud to take advantage of critical gaps in the world of lending. The criminal operation used fraudulent loan applications to purchase vehicles, surpassing $10 million. The operation focused on the luxury market, targeting high-end brands like BMW and Mercedes. The process would begin with the employment of a “straw purchaser” who was given an inflated income of over $284,000, as well as falsified employment records that could bypass verification systems through the use of falsified transportation-related LLCs.

This operation is a stark, real-world example of the most dangerous and significant threat facing lenders today: Synthetic Identity Fraud (SIF). In 2024, total financial fraud loss exposure in the auto lending industry hit a record $9.2 billion, a 16.5% increase over the previous year. Out of the $9.2B, an estimated $2.5 billion, or 27%, was attributed directly to SIF. This makes it the single most significant component of the fraud crisis in auto lending.
Unlike traditional identity theft, where a criminal steals and uses a real person’s legitimate identity for fraudulent activities, synthetic identity theft (SIF) is far more insidious. SIF involves the creation of “phantom identities,” ghosts in the lending machine made of entirely fictitious borrowers that have been meticulously and painstakingly constructed through a blending of real and fake information. The most frequent starting point is often a valid but unmonitored Social Security Number (SSN), typically harvested from the most vulnerable population. A study by Carnegie Mellon’s CyLab found that children’s SSNs are 51 times more likely to be used in synthetic identity fraud because the crime can go undetected for years, or even decades, until the child is old enough to apply for their own credit.
The core challenge of synthetic ID fraud lies in its design: there is no single, real victim who can report a stolen identity or a crime. The SSN owner is unaware, and the lender simply sees a default. This lack of a complainant breaks the traditional fraud reporting and detection feedback loop, allowing these “ghosts” to persist and multiply within a lender’s portfolio. The only way to combat this sophisticated, patient, and increasingly automated form of fraud is to utilize advanced AI analytics, which can uncover the complex, hidden behavioral patterns that legacy systems were never designed to detect.
Synthetic Identity Fraud is not a single act but a methodical, multi-stage process. Understanding how Synthetic Identities are built is critical to grasping why traditional techniques to prevent synthetic identity frauds are ineffective. Fraudsters have learned to exploit the very financial systems and processes designed to establish and develop legitimate credit.
Building an SIF profile begins by harvesting the raw materials from valid data. In 2024 alone, over 2.9 billion consumer records were compromised, leaking personal information, including Social Security Numbers (SSNs). The primary target of this type of identity theft is often a child, an aging adult, or a deceased individual. All have the unique advantage (for Fraudsters) of having inactive or seldom reviewed credit activity.
The stolen SSN is then used as the basis of an identity built upon fabricated details: a false name, date of birth, and address, to create a “Frankenstein ID.” Fraudsters will then legitimize these identities from scratch by utilizing Credit Profile Numbers (CPNs), essentially stolen or unused SSNs marketed by illegal credit “repair” services as a way of gaining a “fresh start.”

Once a synthetic identity is created, the process of nurturing it to build a seemingly creditworthy borrower begins. The “nurturing” of synthetic fraud can take anywhere from 12 to 18 months and is typically initiated by applying for a loan or credit card with the specific goal of being denied. The denial of credit, while counterintuitive, is a critical first step since it prompts the major credit bureaus to create a new credit file for the identity, legitimizing its very existence.
From there, fraudsters employ several tactics to build a positive credit history:
This patient nurturing process exploits the very rules designed to help legitimate “thin-file” consumers build credit. The system sees what appears to be a new-to-credit individual responsibly managing their finances, when in reality it is a criminal enterprise cultivating an identity for a future heist.
This is the endgame. After months or years of careful nurturing, the synthetic identity has a respectable credit score and access to significant lines of credit. Auto loans are the prime target for monetization due to the high value of the loan and the liquidity of the asset. A vehicle can be quickly driven off the lot and resold, shipped overseas, or have its VIN altered, making recovery nearly impossible.
The final act is the “bust-out.” The fraudster maxes out every available credit line — the auto loan, credit cards, personal loans—with no intention of repayment, and then simply vanishes. The synthetic identity becomes a ghost once more, leaving the lender to absorb the total loss.
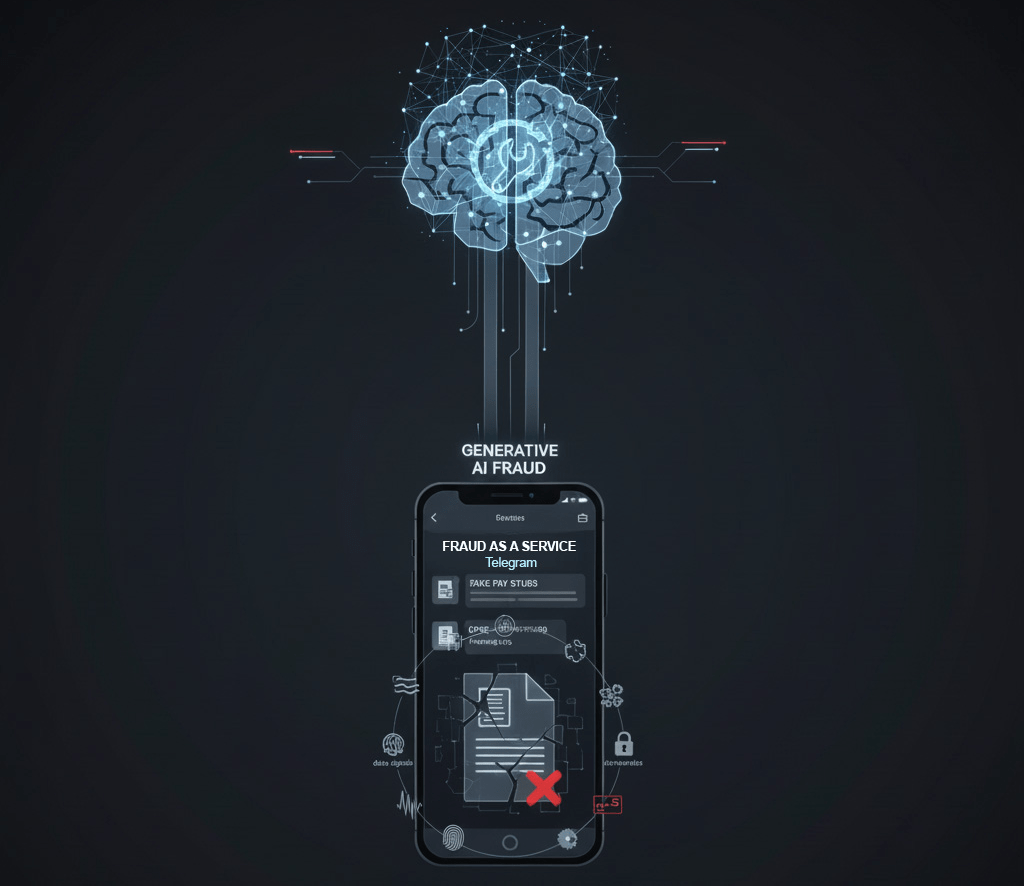
This already sophisticated process is now being industrialized by modern technology. Generative AI is being used to “turbocharge” fraud by automating and scaling the creation of multiple identities and, most critically, hyper-realistic counterfeit documents. AI-powered tools can now generate fake pay stubs, bank statements, and utility bills in seconds that are virtually indistinguishable from genuine ones, easily fooling both human reviewers and traditional document and identity verification systems.
Fraud-as-a-Service (FaaS) platforms offer such capabilities packaged and sold as a service, operating on encrypted messaging apps like Telegram. These marketplaces provide everything from pre-made CPNs and false employment verification to complete phishing kits, putting sophisticated fraud capabilities into the hands of even low-end criminals.
This technological shift presents a new paradigm for lenders. The complex challenge is no longer about verifying the authenticity of a single document; it is about establishing the provenance and legitimacy of an entire identity through a holistic analysis of all its associated data signals. A perfect PDF of a pay stub is no longer proof of anything.
The explosion of SIF is not just a story of more sophisticated criminals; it is also a story of outdated defenses. Lenders have invested heavily in fraud prevention technology, yet losses continue to mount. This is because legacy systems are fundamentally ill-equipped to detect a threat with the unique characteristics of fraudulent identities.
The entire fraud alert ecosystem is built on a simple premise: when a crime occurs, a victim reports it. A bank, a credit bureau, or the Federal Trade Commission triggers investigations and alerts based on an initial fraud report, which helps prevent further damage. SIF is architected to bypass this feedback loop completely. Since they are fabricated identities, there is no one to file a complaint. The owner of the stolen SSN is unaware, and the lender, seeing only a default, has no initial reason to suspect a crime. This silence is what makes SIF so pernicious; it can operate for years without setting off the alarms that legacy systems rely on.
Legacy fraud detection systems are predominantly rule-based. They perform a “point-in-time” analysis at the moment of application, checking for red flags like known fraudulent addresses, mismatches between name and SSN, or a high velocity of recent applications. These systems are fighting yesterday’s war.
SIF is a “long con” explicitly designed to evade these static rules. Fraudsters build their synthetic profiles with patience, mimicking the behavior of legitimate consumers over months or years, maintaining a clean record, paying bills, and staying below the radar of rule-based triggers. The most powerful predictive signals of SIF are not present in the application data itself, but in the subtle behavioral patterns that unfold over time—a dimension to which point-in-time analysis is completely blind.
The most powerful fraud signals often lie not in individual data points, but in the hidden relationships between those data points, especially across siloed systems like a Loan Origination System (LOS), credit bureau data, device logs, and bank account transaction histories. For instance, using a single device ID to submit multiple, seemingly unrelated loan applications is a significant red flag. The same is true for a physical address linked to a known shell company or various applicants, all “piggybacking” on the same obscure authorized user tradeline. These relational patterns are virtually invisible to systems that analyze each application in isolation, a direct consequence of the organizational and technical silos that prevent a unified view of applicant data and struggle to identify synthetic identities.
The ultimate failure of legacy systems occurs when a loan of fake identities defaults. In the absence of a clear fraud signal, the loss is almost always misclassified and written off as a standard credit loss. The misclassification has two devastating consequences.
First, it systematically underreports the accurate scale of the SIF problem. The $2.5 billion cited earlier is likely just part of the reported problem, representing only cases where lenders actually identified identity fraud. The real cost is buried within lenders’ credit portfolios, leading risk departments to believe that defaults are rising due to economic factors, when a significant portion is actually due to organized crime.
Second, and more dangerously, it pollutes the historical data used to train the next generation of credit risk and fraud models. By labeling fraudulent accounts as simple credit defaults, lenders inadvertently teach their models to accept the characteristics of synthetic identities as part of the typical credit risk spectrum. The well of data from which the models drink is poisoned, making them progressively less effective at detecting the very threat they are supposed to prevent.
| Auto Originator | Credit Washers | Other Consumers |
|---|---|---|
| Super Prime | 3.4% | 0.1% |
| Prime Plus | 4.8% | 0.4% |
| Prime | 5.4% | 1.2% |
| Near Prime | 6.6% | 3.4% |
| Subprime | 14.4% | 10.4% |
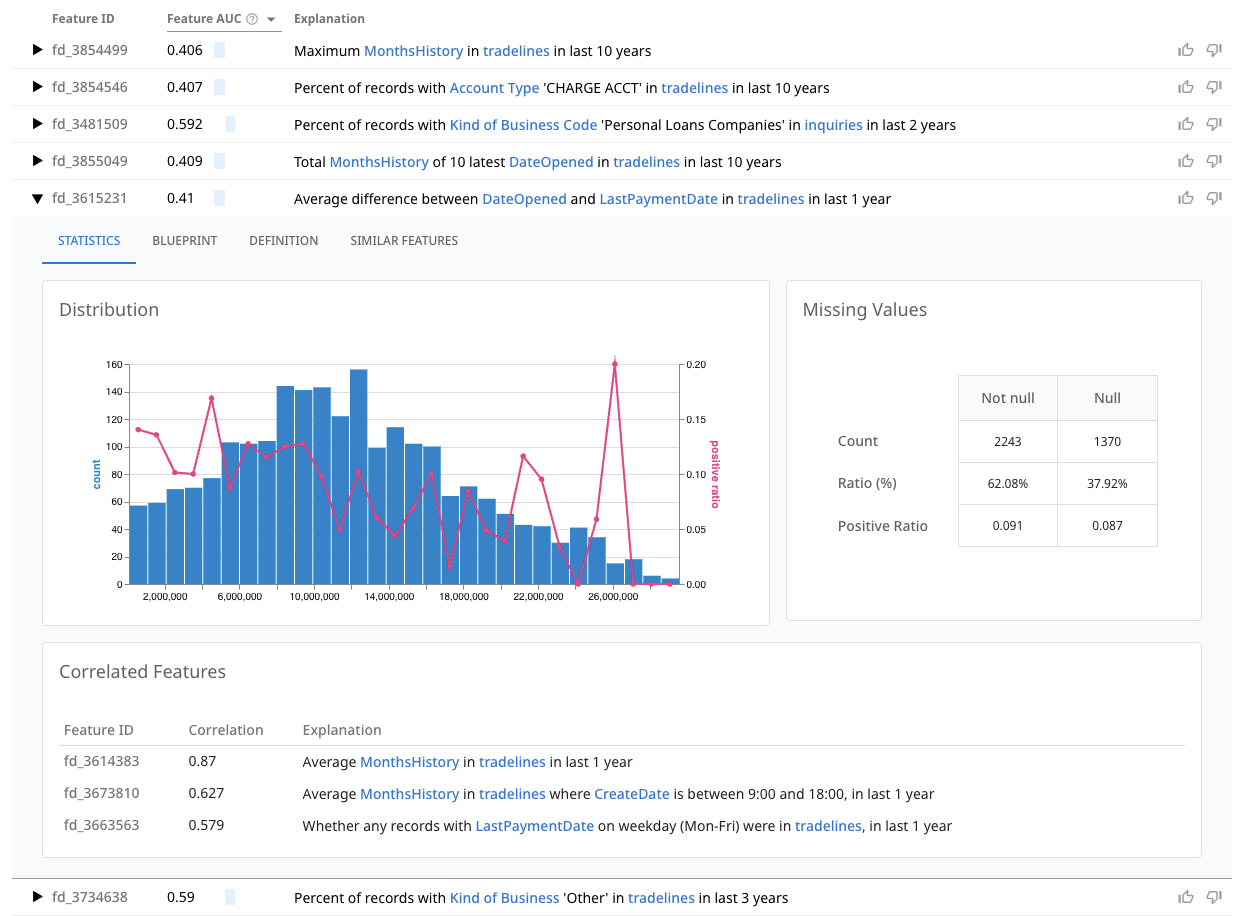
To combat a threat as dynamic and patient as SIF, lenders must move beyond writing more complex rules for their legacy systems. A fundamental paradigm shift is required: from analyzing static data points to automatically discovering dynamic, behavioral signals hidden across all available data. A simple data point, such as a FICO score, offers a limited, one-dimensional perspective. A powerful behavioral feature, on the other hand, captures the context and evolution of an applicant’s profile. Consider the difference between FICO Score = 720 and a feature like (Rate of FICO score increase) / (Age of oldest tradeline). The latter is far more effective at spotting a manufactured credit profile that is being artificially inflated at an unnatural pace—a classic hallmark of SIF nurturing. Discovering thousands of these multi-dimensional behavioral signals is the key to unmasking the ghosts in the portfolio.
For data science teams on the front lines of building and maintaining fraud models, dotData Feature Factory provides the tools to overcome the limitations of manual feature engineering and polluted historical data. As a Python library, it integrates seamlessly into existing data science workflows, easily run in a Jupyter notebook or the like. Imagine a data scientist tasked with improving their organization’s SIF detection model. The workflow becomes dramatically more powerful and efficient:
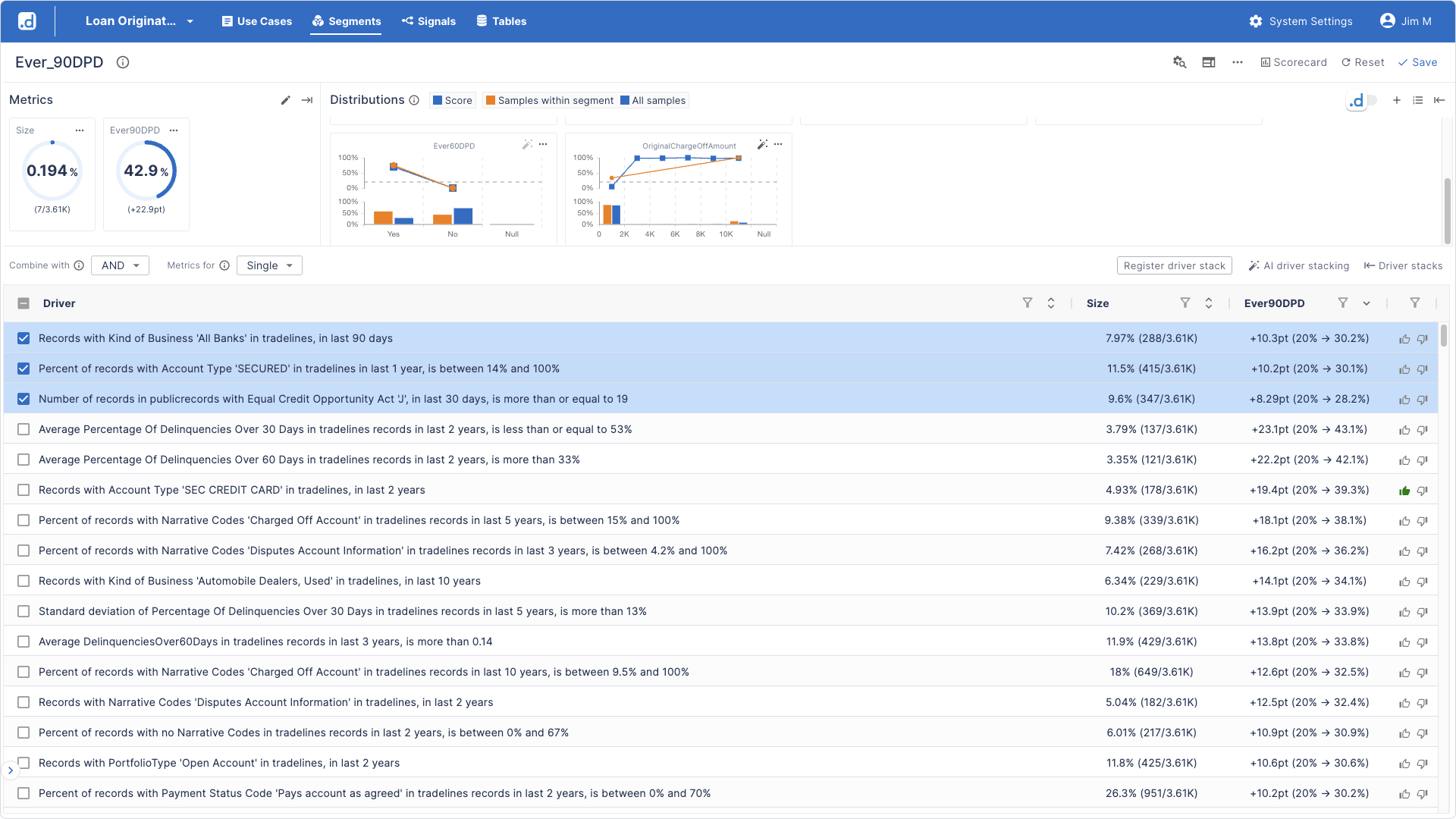
For risk managers, business analysts, and other decision-makers who need to understand and act on fraud risk without writing code, dotData Insight provides an intuitive, point-and-click GUI. It translates complex data relationships into clear, actionable business drivers. A risk analyst using Insight can quickly move from data to decision:
This micro-segment perfectly describes the behavioral footprint of a nurtured synthetic identity: an entity that (1) appears to have built its recent credit file using secured credit cards (2) has a bizarre and impossibly high number of recent joint public records and (3) is actively opening new bank tradelines “right now.” This is not just an interesting statistic; it is an immediately actionable underwriting rule that needs to be explored.
Synthetic Identity Fraud is no longer an emerging threat; it is a multi-billion-dollar crisis that is actively targeting the auto lending industry. Supercharged by Generative AI and industrialized by Fraud-as-a-Service platforms, this threat is evolving faster than traditional defenses can keep up.
Legacy, rule-based systems are failing. They are fundamentally blind to the patient, long-term, and cross-silo behavioral patterns that define SIF. They are fighting a new war with old weapons, leading to massive, often misclassified, financial losses and poisoned data that weakens a lender’s analytics over time.
The only practical solution is to make a strategic shift: from analyzing static, isolated data points to automatically discovering the complex, hidden behavioral signals across all of an organization’s data. This is precisely what dotData delivers. By empowering the entire organization—from the data scientists building predictive models with Feature Factory to the risk managers making critical underwriting decisions with dotData Insight—lenders and financial institutions can finally move from a reactive to a proactive posture.
The ghosts in your portfolio are real, and they are costing you millions. Stop chasing them with outdated methods.
Learn how dotData Feature Factory and dotData Insight can help you stay ahead of fraudsters in lending.
SIF is a type of fraud where criminals create “phantom identities” using a blend of real social security numbers and stolen personal data from vulnerable populations, and fabricated information to construct fictitious borrowers. It’s not traditional identity theft because no single, clear victim exists to report the crime.
In 2024, total fraud loss exposure in the auto lending industry hit a record $9.2 billion, with an estimated $2.5 billion (27%) attributed directly to SIF, making it the largest component of fraud in auto lending.
Traditional systems are often rule-based and perform “point-in-time” analysis, making them blind to the long-term, behavioral patterns of SIF. Since the ID is false, the traditional fraud reporting feedback loop is broken, and losses are often misclassified as credit losses, polluting historical data.
AI-powered advanced analytics, like dotData Feature Factory and dotData Insight, shift the focus from static data points to automatically discovering dynamic, behavioral signals hidden across all available data. This allows for the identification of complex, often hidden patterns of potential fraud, credit manipulation and rapid account accumulation that legacy systems miss.
Generative AI “turbocharges” SIF by automating and scaling the creation of synthetic profiles and producing hyper-realistic counterfeit documents (e.g., fake pay stubs, bank statements) that can easily fool traditional verification systems. This has led to the rise of “Fraud-as-a-Service” platforms.