
Demystifying Feature Engineering for Machine Learning
- Thought Leadership
FE is the process of applying domain knowledge to extract analytical representations from raw data, making it ready for machine learning. It involves the application of business knowledge, mathematics, and statistics to transform data into a format that can be directly consumed by machine learning models. It starts from many tables spread across disparate databases that are then joined, aggregated, and combined into a single flat table using statistical transformations and/or relational operations.
Let’s say you are addressing a complex business problem such as predicting customer churn or forecasting product demand using applied machine learning. Assuming a team is in place and the business case identified, where do you start? The first step is to collect the relevant data to train the machine learning (ML) algorithms. This is usually followed by the selection of the appropriate algorithm or ensemble of algorithms.
Choosing the right algorithm depends on the business goals (Accuracy vs Interpretability), category of the problem (Regression or Classification), nature of data (Categorical or Numerical), desired outcome, and constraints (computational resources, training time, latency). Irrespective of the choice of algorithm, whether it is logistic regression, decision tree, boosting, or neural networks, there is a fundamental requirement of providing high-quality input data containing relevant business hypotheses and historical patterns aka Feature Engineering (FE). Often the algorithms get all the limelight and many people believe that algorithms are the secret weapons in the AI battle. But it is FE that performs the magic behind machine learning.
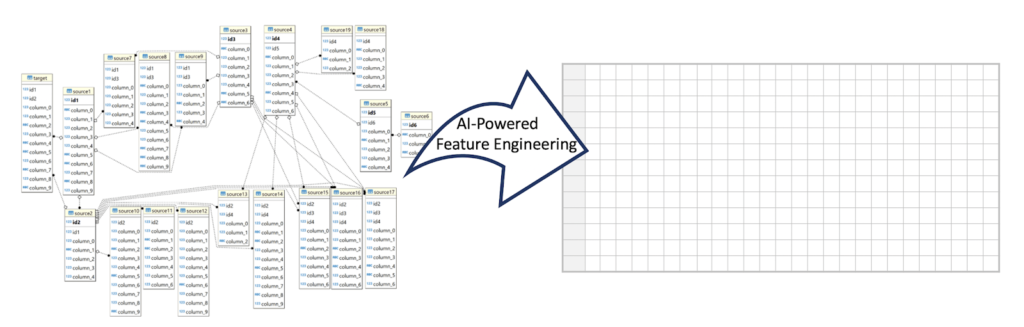
Practical FE is far more complicated than simple transformation exercises such as One-Hot Encoding. To implement FE, you need to write hundreds or even thousands of SQL-like queries, performing a lot of data manipulation, as well as a multitude of statistical transformations.
ML is driven by algorithms and the algorithms are dependent on data. If you know the historical data, you can detect the pattern. Once you uncover a pattern, you can build a hypothesis. Based on the hypothesis, you can predict the likely outcome such as which customers are likely to churn in a given time period. FE is all about finding the optimal combination of hypotheses.
FE is critical because if you provide the wrong hypotheses as an input, ML cannot make accurate predictions. The quality of any provided hypothesis is vital for the success of an ML model. Quality of feature is critically important from accuracy and interpretability point of view. FE is the most iterative, time-consuming, and resource-intensive process, involving interdisciplinary expertise. It requires technical knowledge but, more importantly, domain knowledge. The data science team builds features by working with domain experts, testing hypotheses, building and evaluating ML models, and repeating the process until the results become acceptable for businesses.
FE automation has vast potential to change the traditional data science process. It significantly lowers skill barriers beyond ML automation alone, eliminating hundreds or even thousands of manually-crafted SQL queries, and ramps up the speed of the data science project even without a full light of domain knowledge. It also augments our data insights and delivers “unknown- unknowns” based on the ability to explore millions of feature hypotheses just in hours.
These days automated machine learning (AutoML) is gathering a lot of attention. AutoML is tackling one of the critical challenges that organizations struggle with: the sheer length of the AI and ML project, which usually takes months to complete, and the incredible lack of qualified talent available to handle it. While current AutoML products have undoubtedly made significant inroads in accelerating the AI and machine learning process, they fail to address the most significant step, the process to prepare the input of machine learning from raw business data, in other words, feature engineering.
To create a genuine shift in how modern organizations leverage AI and machine learning, the full cycle of data science development must involve automation. If the problems at the heart of data science automation are due to lack of data scientists, poor understanding of ML from business users, and difficulties in migrating to production environments, then these are the challenges that AutoML must also resolve.
AutoML 2.0, which automates the data and feature engineering, is streamlining FE automation and ML automation as a single pipeline and one-stop-shop. With AutoML 2.0, the full-cycle from raw data through data and feature engineering through ML model development takes days, not months, and a team can deliver 10x more projects.
Contrary to popular belief, algorithms are not the most distinguishing features of applied machine learning. FE influences the performance and accuracy of ML models more than anything else. It helps reveal the hidden patterns in the data and increases the predictive power of machine learning. In order for ML algorithms to work properly, you need to provide the right input data that algorithms can understand. Oftentimes this involves complex mathematical transformations on raw data. FE provides that input data into a single aggregated format optimized for ML. It is the secret sauce that enables AI/ML to do the magic. Whether it is preventing fraud in financial services, anomaly detection in manufacturing, or predicting customer churn for insurance companies, feature engineering is the most decisive factor for AI/ML success or failure.


![Automated Machine Learning vs. Data Science Automation [Infographic]](https://dotdata.com/wp-content/uploads/2019/08/battle.jpg)