
Feature Engineering for Categorical Attributes
- Technical Posts
Data is at the heart of Machine Learning and AI. Each dataset will likely have numeric and non-numeric (categorical) attributes. The goal for any machine learning algorithm is to build a formula that predicts some ground-truth target values based on available data.
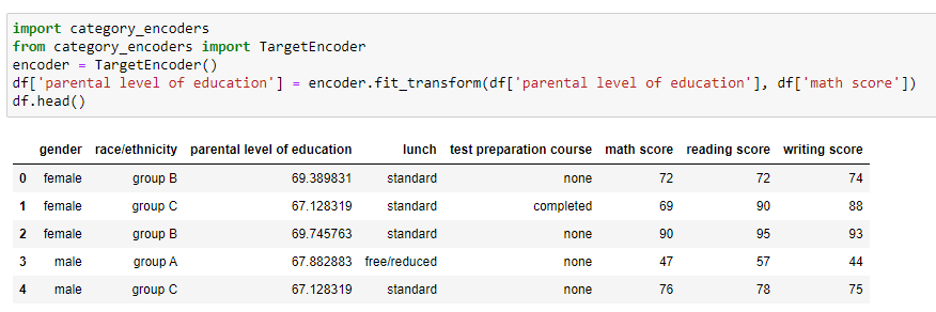
The example data-set shown below is publicly available on Kaggle (Student Performance Data Set | Kaggle). The attributes (gender, race/ethnicity, parental level of education, lunch, test preparation, and course) are categorical, while the attributes (math score, reading score, and writing score) are numeric.
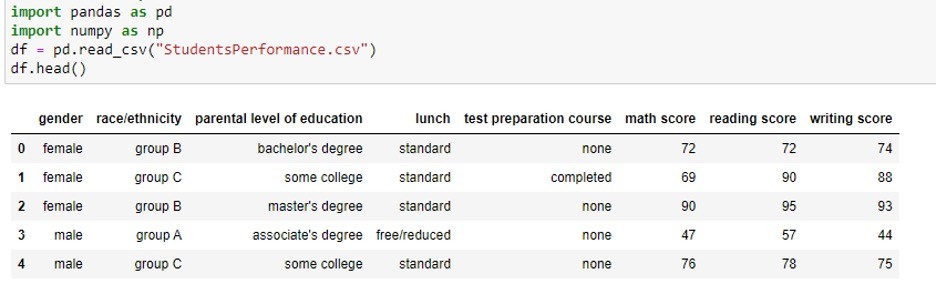
Numerical features are easy to analyze, and their impact on the target value is simple to determine. On the other hand, while some ML algorithms (e.g., tree-based algorithms) can directly handle categorical attributes, many ML algorithms assume the input attributes are numeric. Another problem is that analyzing the “correlation” between a categorical attribute and the target variable is not straightforward. The challenge of categorical attributes is why we often need feature engineering.
In general, feature engineering manipulates and transforms data to extract relevant information to predict the target variable. The transformations of feature engineering may involve changing the data representation or applying statistical methods to create new attributes (a.k.a. features).
One of the most common feature engineering methods for categorical attributes is transforming each categorical attribute into a numeric representation. Transforming categorical data into numeric data is often called “categorical-column encoding” and creates a new numeric attribute that is tractable for many ML algorithms. Categorical-column encoding allows data scientists to quickly and flexibly incorporate categorical attribute information into their ML models.
The goal of creating a numeric representation (the feature) is to capture and conserve the relationship between the categorical attribute and the target variable. This blog will review and discuss popular categorical-column encoding methods by taking the student performance dataset as an example.
dotData Py: AutoFE for Python Data Scientists
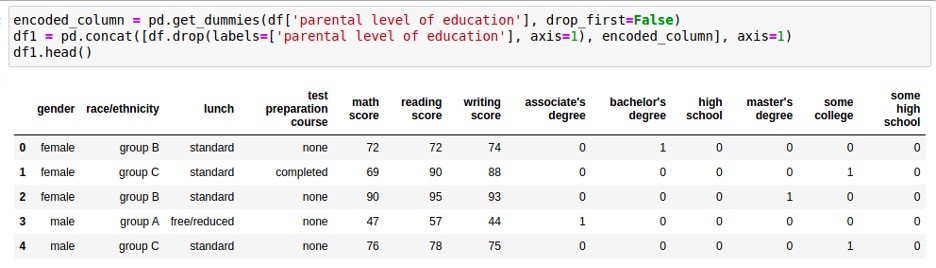
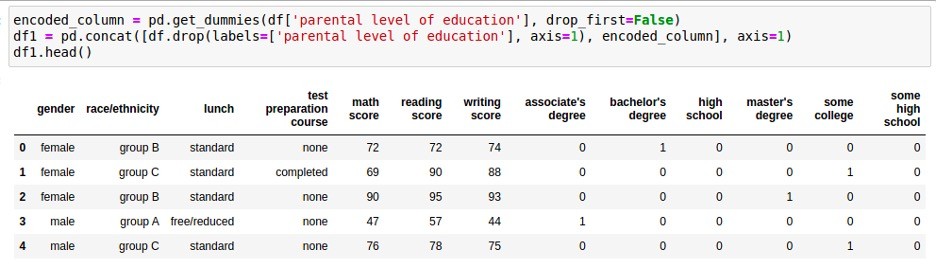
One-hot encoding is the simplest and most basic categorical-column encoding method. The idea is to have a unique binary number of multiple digits for each category. Hence, the number of digits is the number of categories for the categorical attribute to be encoded. The binary number has one digit as 1 and the rest zeros, hence the name ‘one-hot.’
For example, if the category is male or ‘female,’ then ‘male’ can be represented by 10, and 01 can represent ‘female.’ For simplicity, we can ignore the right digit from these examples with ‘male’ represented by 1 and ‘female’ expressed as 0. The same idea applies to cases with more than two categories. In the general case with N categories, the number of digits is N-1.
One-hot encoding treats each digit out of N-1 digits as a new column and allows removal of the original categorical column. The main advantage of one-hot encoding is that it maps the categorical column into multiple easy-to-use binary columns. Also, each new column corresponds to a category in the original categorical column, making understanding the meaning of one-hot encoding features straightforward.
A disadvantage of this method is that it eradicates the ability to represent any kind of ordinal relation between the categories within each attribute. For example, in the case of “parental level of education,” “master’s degree” is a higher degree than “bachelor’s degree.” However, one-hot encoding features cannot express such ordinal relations among categories.
Another inherent disadvantage comes when dealing with a categorical attribute with high cardinality (many categories). For example, the “product category” column in a retail dataset may have 1,000,000 categories (the number of products). If we apply one-hot encoding to this column, we must add almost one million new columns. Such a high-dimensional feature representation often causes undesired consequences like high training variance (eventually decreasing accuracy), significant computation and memory consumption, etc..
Label encoding is another well-known and straightforward method that maps the categorical values into ordinal numbers starting from 0 to N-1. Each category value is assigned to a unique integer -or non-integer- value within the chosen range. For example, (“bachelor’s degree,” “some college,” “master’s degree,” “associate’s degree”) can be mapped to (0, 1, 2, 3).
Label encoding is straightforward to implement and solves the problem encountered in using one-hot encoding with high cardinality columns. In addition, label encoding allows introducing ordinal/taxonomy relations among categorical values into the feature.
The main challenge of label encoding is the determination of the category order. With an appropriate order, label encoding captures essential characteristics of the original categorical values. Without proper order, however, label encoding performs poorly and results in features that are hard to understand. While a few simple heuristics can help, such as random permutation, value frequency, or expert judgment (manual), it is often tough to make these heuristics work reasonably with many categories.
Unlike one-hot and label encoding, which are conducted only on the original categorical attribute, target encoding finds the mapping from categorical values to numeric values using a target variable. Target encoding assigns similar numeric values to two categorical values if their relations with the target variable are similar (and vice versa). Thus, the target encoding features represent the target values which often positively influences the model training process.
The following example illustrates label encoding (frequency-based order) and target encoding for a classification problem. In this example, a simple likelihood-based method is used for target encoding. The higher the value of the target encoding feature, the higher the corresponding category is correlated with the target variable.
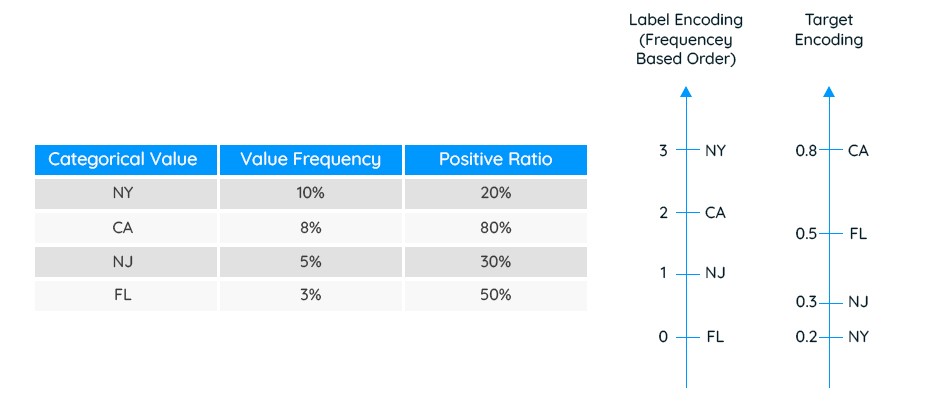
One disadvantage of target encoding is that it needs a large number of data points to avoid overfitting. For example, if “WA” only takes up one row in the data set above, it will have a Positive Ratio of 100%. In this case, the value of target encoding for “WA” is not reliable.
There are advanced tools on the market to mitigate these problems. dotData’s platform, for example, applies an advanced target encoding method using a regularization technique to mitigate overfitting for small datasets (or high cardinality categorical attributes). The degree of regularization is automatically tuned to maximize the prediction power of the target encoding feature.
As much as feature engineering is critical to machine learning, encoding is a crucial step in feature engineering, mapping the categorical values into representative numerical values.
This blog explained one-hot encoding, label encoding, and target encoding and compared their advantages and disadvantages. There is no “golden” method in a practical ML project, and you should select appropriate encoding methods by analyzing data characteristics. In dotData’s platform, one-hot encoding and advanced target encoding with regularization are automatically tested, and the most relevant categorical encoding features are selected for your machine learning algorithms.


