Feature Factory is a fundamental shift in how enterprise data science teams develop curated data and accumulate data know-how as reusable assets. Feature spaces and the ability to discover features through a data-centric, programmatic approach leads to enhanced collaboration, better efficiency, increased model quality, greater reusability, reproducibility, scalability, and transparency. Break down silos and capitalize on the wealth of information at your disposal.
dotData Feature Factory Data-Centric & Programmatic Feature Discovery
Empower data scientists with automated feature discovery to make it easier for them to use all your data in building better, more accurate ML models.
A Paradigm Shift
for Enterprise Data
Automated Feature Engineering to Maximize
Data Value and Empower AI
Feature engineering is essential for maximizing data value and advancing AI. Traditionally, it’s been a manual, time-intensive process relying on experience and intuition. dotData Feature Factory transforms this through a data-centric approach, programmatically defining feature spaces to automatically generate a vast array of feature hypotheses, impossible to achieve manually. By archiving user data and business insights in an analysis database it enables process reuse. Feature Factory automates feature pipeline creation for production deployment, supplying processed data to support AI development, business intelligence, and other data applications, empowering all data-driven initiatives.

Product Features
dotData Feature Factory transforms corporate data processing know-how into reusable assets through unique feature engineering to discover business patterns hidden in business data. It effectively transforms large volumes of data accumulated by companies into business insights to realize data-driven decision-making.
Multi-Source, Multi-Table Feature Engineering
Quickly connect to diverse data sources to enrich feature discovery and unlock iterative feature additions from new sources.
No SQL Required
Leverage dotData Feature Factory to interact with data through Dataframes and generate entity relationships and features using familiar Python commands and syntax.
Automated Data Wrangling
Avoid time-consuming and error-prone data wrangling, dotData will automatically cleanse, align, and prepare data for feature discovery.
Time-Series Features, Without Leakage
Automatically generate and validate multidimensional time-based features, including holidays, lags or delays, periodicity, seasonality, and more.
Build Reusable Feature Discovery Assets
Record every data and feature transformation step into your Analytic Database and turn your “know-how” into reusable assets for your organization.
Automated Feature Discovery at Enterprise Scale
Generate and score millions of data features from complex tables, relationships, and billions of rows.
Insights and Explainable AI
Produce actionable business insights and explainable features from natural language descriptions and blueprinting of discovered features from source variables.
Production-Ready Feature Pipeline Generation
Automatically generate feature pipelines with full SQL code from source tables, ready for production use.
Steps to Use
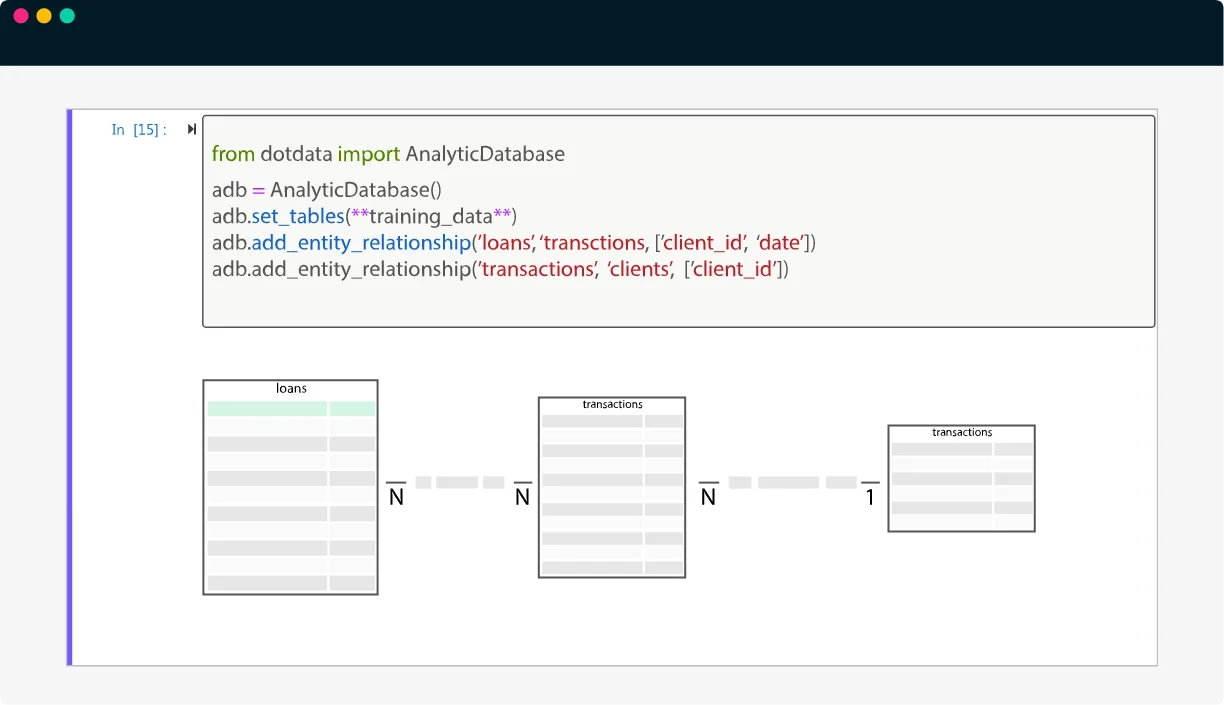
Connect to multiple data sources, data lakes, or data warehouses and ingest the data as Spark Dataframes in Python
- Load data from modern cloud data marts (including Amazon Redshift, Google Big Query, Snowflake, MS Azure Synapse), traditional data warehouses (Oracle, Teradata, and MS SQL Server), and flat data sources (CSV files, Tableau Hyper files, etc.) via Spark Dataframe API.
- Automatic data type detection and data schema inference.
- Connect multiple data sources together by specifying Dataframe relationships.
- Define and configure temporal data relationships for automated temporal feature discovery.
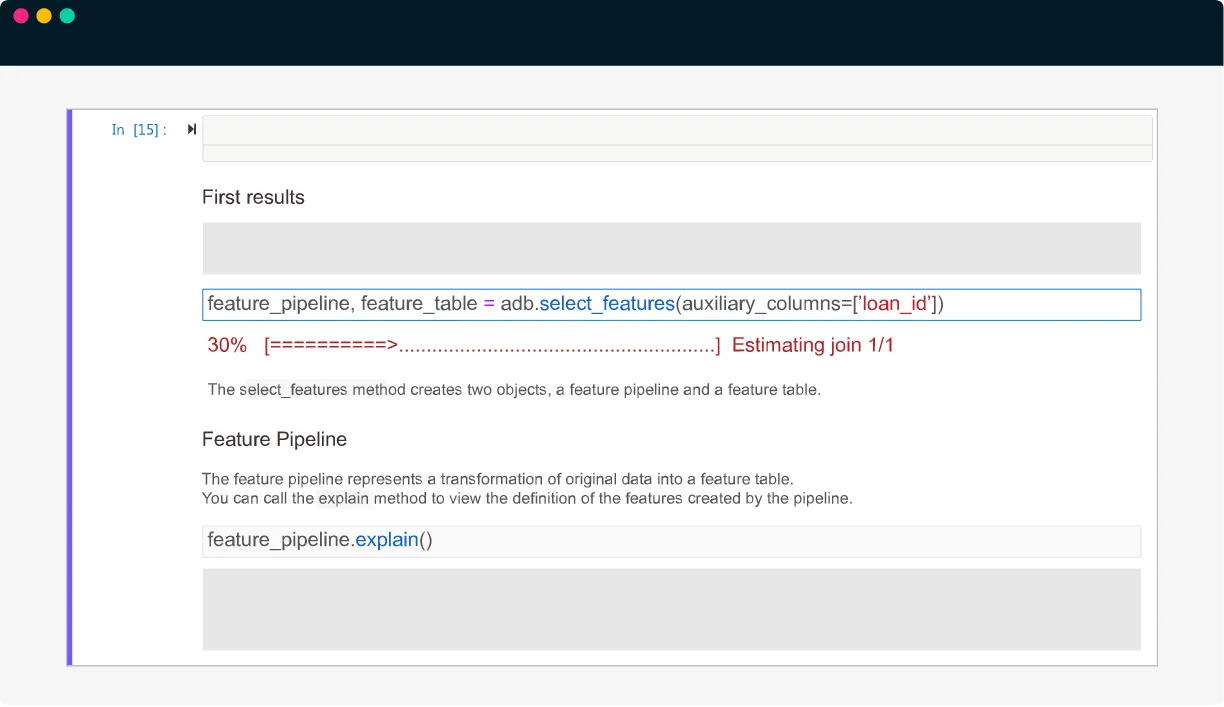
Specify your target variable and the source tables as Dataframes you will use to build features. Define your search criteria and run dotData Feature Factory from your favorite Python IDE or notebook
- Resolve data quality issues like illegal values, outliers, data canonicalization, missing values, target label mapping, and more.
- Explore millions of feature hypotheses – including numeric, categorical, time-series, text, and even geospatial data.
- Resolve feature over-fitting, feature collinearity, feature drifts, and feature redundancy based on dotData’s proprietary algorithms.
- Custom feature primitives and search criteria to add your own domain features into the feature exploration space.
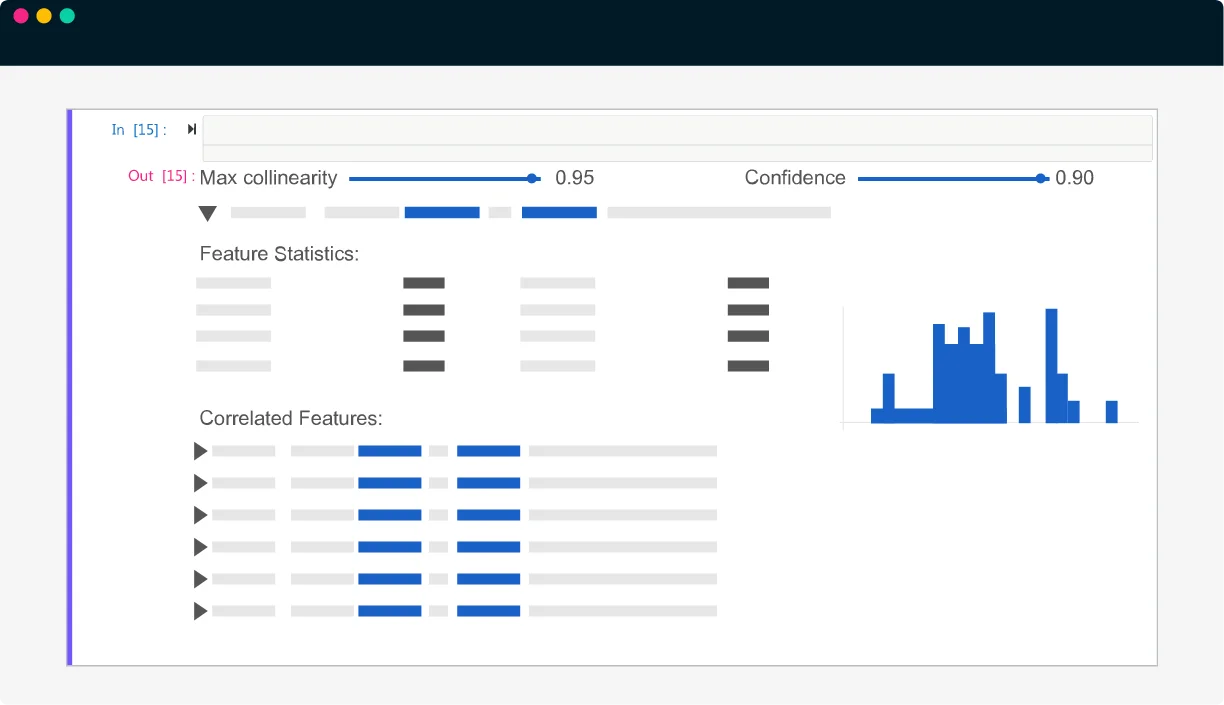
Explore and evaluate discovered features interactively from Python
- Feature leaderboard (feature list) that surfaces features that are the most relevant and correlated with your target variable.
- Understand each feature’s business value and construction via an easy-to-understand auto-generated explanation and feature blueprint diagram.
- Select your preferred features based on various feature metrics like correlation, feature-wise AUC, permutation importance, feature locality, popularity, and more.
- Extract feature tables as Dataframe and visualize each feature using the built-in visualization tool or any Python visualization library you like.
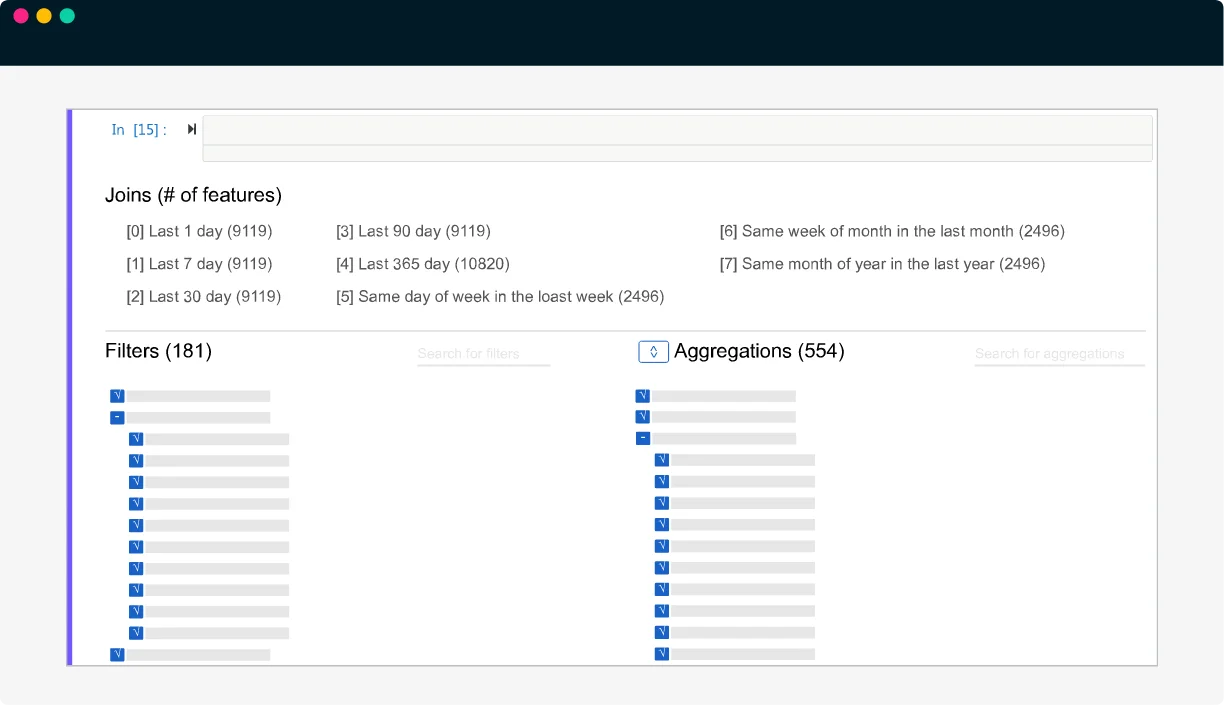
Iterate feature discovery experiments to derive better quality and higher-order features. insightsExplore, optimize, and tune features interactively. Choose which features to extract for further analysis, modeling, or reporting from within Python
- Edit feature descriptors (definitions) to customize discovered features and leverage your domain expertise.
- Natural interface to add new datasets and run new experiments. Combine features from multiple experiments with different granularity.
- All steps and feature space details are reported without any black box.
- Modularized execution allows you to run your experiments from any intermediate steps and iterate them faster.
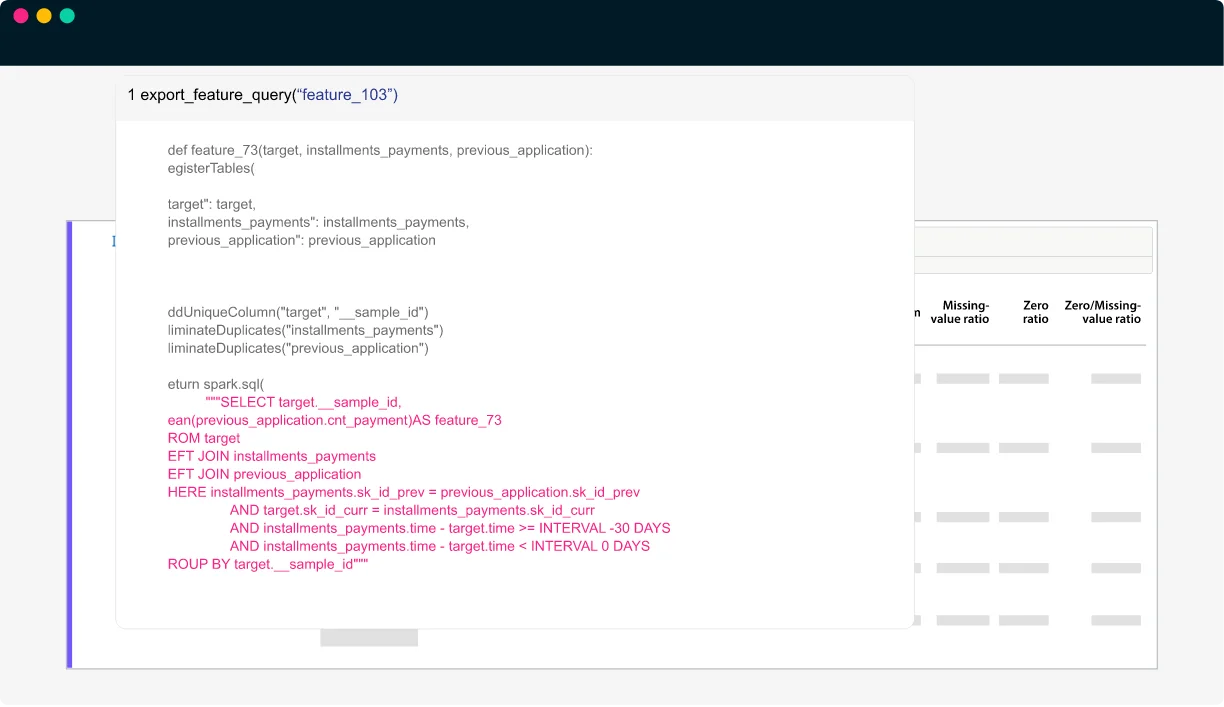
Populate feature stores and continuously update features in production applications
- Ingest features and metadata (feature explanation, feature statistics, feature schema) into any feature stores (Databricks, Snowflake, AWS SageMaker and more) and enhance your ML models.
- Automatic feature pipeline generation with fully specified query statements for reuse and eliminate error-prone manual feature query implementation.
- One command deployment of feature pipelines into dotData Ops. Continuously recalculate features values with the newest data and monitor feature quality and drifts.
Deployment Options
Jupyter Notebook
Install and use dotData Feature Factory on Jupyter Notebook, the standard Python environment for data scientists.
Databricks
Seamlessly integrate dotData Automated Feature Discovery into Databricks Python workflows and ML experiments.
Snowflake
dotData Feature Factory is available on Snowflake via Snowpark Container Services.
Amazon EMR
Install dotData Feature Factory in your AWS EMR instance to accelerate feature discovery for your data science team.
Pip Install
Quickly deploy dotData Feature Factory via pip-install – even on your own personal laptop.
What Our Customers Say
sticky.io
I was spending 95% of my time wrangling data…now I can offload most of that work and just focus on delivering viable patterns and insights.
Exeter Finance
The biggest problem is that, when doing it manually, it’s just a repetitive, trial-and-error process that takes time. dotData solves a problem I’ve been trying to solve for 20 years.
JAL Engineering Co., Ltd.
With dotData, it is now possible to create new features that can lead to signs of problems that could not be found through hypothesis-testing analysis based on the knowledge of mechanics and engineers.
News
Press Release
dotData Announces dotData Feature Factory 1.3 with Enhanced AI-Powered Feature Discovery and Expanded LLM Support
Press Release
dotData Announces dotData Ops 1.4 with Advanced Python Ecosystem Integration
Press Release
dotData Announces Updates to Products Enhanced with Generative AI Integration
Press Release
dotData Announces dotData Insight for Salesforce – A Revolution in Sales and Marketing Analytics
Press Release
dotData Announces dotData Feature Factory 1.1 with GenAI-Powered Assistance
dotData's AI Platform Maximize Data Utilization through Feature Discovery
dotData leverages automated feature engineering to build models using machine learning, enhancing data by accumulating feature values as assets and extracting valuable insights, enabling businesses to become more data-driven. Our platform satisfies a wide range of needs, including business transformation, and support the effective use of data and AI to drive innovation and growth.
Request a Demo
We offer support tailored to your needs, whether you want to see a demo or learn more about use cases. Please feel free to contact us.


