Reducing Customer Churn in the Insurance Industry with Machine Learning
Industry Use Cases
Sharada Narayanan
Join Our Newsletter
AI automation can solve a variety of problems and address multiple Insurance use cases
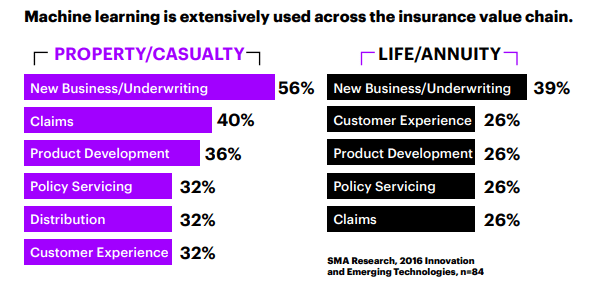
The insurance industry is one of the earlier pioneers of making data-driven decisions and adopting Machine Learning. Over the last few years, the amount of data has exploded and insurance companies are turning a lot more to AI and ML to help process large quantities of data to drive innovative business decisions keeping the customer at the top of their minds. With the increase in the volume and variety of data and the needs of the insurance industry, the types of problems that are aimed to be solved with AI and ML have increased tremendously. The below visual gives a sneak preview into the Insurance business areas where machine learning can be leveraged and how often insurance companies are considering incorporating ML into that business area.
Figure: % of Insurance companies that are considering incorporating ML into specific Insurance business areas
Given the variety of problems to be solved using ML, there exists a constraint on the Data Scientists’ time forcing the Data Scientists and companies to focus on one problem at a time. This gets us thinking about the opportunity cost of missing out on bringing more of these ML solutions to the business sooner. Could we accelerate this process of incorporating ML know-how and best practices to help Data Scientists bring more meaningful ML solutions to the business quicker?
Insurance Churn Reduction Case Study
One of the top workers’ compensation insurance companies solved a variety of problems using ML and AI automation. The use cases covered areas such as identifying potentially churning policyholders, predicting the chance of a new customer coming on board, predictions to improve the claims processing and other operations, and more. All these use-cases were performed in under 6 months by leveraging AI Automation. In this blog, we’ll look at one of the popular use cases – predicting which customers are likely to continue with their policy and identifying those that are likely to churn.
The Data:
To predict if a policyholder will cancel their insurance policy, we first need historical data about the policyholders who did cancel. The historical data available spanned over 4 years of policyholders including hundreds of thousands of policyholders who had historically renewed and a subset of policyholders who had canceled their policy. To assist in making these predictions, data related to the policyholders’ location, type of policy held, anonymized demographic information, and more were used.
The Challenges:
Imbalanced data is the problem of having very few bad cases to predict, which occurs in various industries. This is a great problem to have for the business where they have very few policy cancellations and it is the ultimate goal of solving this ML problem too. But this in turn makes it much harder for the machine to learn patterns from the data to help identify the policy holders who will cancel. To handle this problem, the Data Scientist will have to try various techniques of data balancing to ensure the model can learn effectively. dotData, having incorporated a lot of the industry best practices to handle imbalanced data, was able to automatically handle this problem to produce a highly accurate prediction of policy cancellations
Considering the data elements mentioned above, very often the data comes from different sources and needs to be consolidated, cleaned and brought to the correct format to create the machine learning model – in other words, AI data prep. AI data prep is often the most time consuming step in machine learning and can take up to months to prepare the data in the right format and engineer the required features. dotData’s unique Auto Feature Engineering capability allowed for the Data Scientist to apply very minimal data pre-processing and leverage the automated features created by dotData to improve the accuracy of the models
The Solution:
Accelerated model building: Using dotData, the Data Scientist was able to pass raw data in a minimally processed form and build out over 500 features and 100s of models in a span of 2 hours. These 100s of models explore various combinations of features, data balancing techniques, algorithm types and hyperparameter combinations for the Data Scientist to choose from, giving the Data Scientist the power to pick the model and features that are best suited for the business at a highly accelerated pace!
Improved Accuracy: The final dotData model was able to provide 20% higher accuracy than the existing solution, providing a huge gain in business value to the company
Ease of Experimentation: Given that dotData can explore various features and models and automatically pick the best combination to solve the problem, this helps the Data Scientist focus on incorporating various combinations of datasets and think more about how the dotData features can be applied in the business
dotData’s unique value:
Built and produced a production deployable model in less than 2 weeks
Produced 100s of models to help pick the best in a matter of a few hours
Produced 1000s of interpretable features to improve the model performance and help explain the model and drive insights for the business
Driving large-scale automated feature exploration and automated model building give the Data Scientist the power to investigate many model combinations and to bring the business early on into the model development process thus increasing trust and transparency in the final ML solution released into the business.
This allows the Data Scientist to think about other real complex problems that can be solved with AI/ML. The insurance provider has only just opened up Pandora’s box of problems that can be solved using AI and by leveraging dotData’s AI automation they aim to accelerate their Data Science path in the insurance industry!
Sharada brings 6+ years of experience in Data Science and Machine Learning to dotData. Sharada is an integral part of the Customer Success team, supporting the automation of business solutions using dotData's AutoML and Auto Feature Engineering. Sharada’s background includes diverse experiences from the retail and automotive industries working on implementing Machine Learning solutions for Customer Analytics, Supplier Analytics and Purchasing analytics.
dotData's AI Platform
dotData Feature Factory
Boosting ML Accuracy through Feature Discovery
dotData Feature Factory provides data scientists to develop curated features by turning data processing know-how into reusable assets. It enables the discovery of hidden patterns in data through algorithms within a feature space built around data, improving the speed and efficiency of feature discovery while enhancing reusability, reproducibility, collaboration among experts, and the quality and transparency of the process. dotData Feature Factory strengthens all data applications, including machine learning model predictions, data visualization through business intelligence (BI), and marketing automation.
dotData Insight is an innovative data analysis platform designed for business teams to identify high-value hyper-targeted data segments with ease. It provides dotData's hidden patterns through an intuitive, approachable interface. Through the powerful combination of AI-driven data analysis and GenAI, Insight discovers actionable business drivers that impact your most critical key performance indicators (KPIs). This convergence allows business teams to intuitively understand data insights, develop new business ideas, and more effectively plan and execute strategies.
dotData Ops
Self-Service Deployment of Data and Prediction Pipelines
dotData Ops offers analytics teams a self-service platform to deploy data, features, and prediction pipelines directly into real business operations. By testing and quickly validating the business value of data analytics within your workflows, you build trust with decision-makers and accelerate investment decisions for production deployment. dotData’s automated feature engineering transforms MLOps by validating business value, diagnosing feature drift, and enhancing prediction accuracy.
dotData Cloud
Eliminate Infrastructure Hassles with Fully Managed SaaS
dotData Cloud delivers each of dotData’s AI platforms as a fully managed SaaS solution, eliminating the need for businesses to build and maintain a large-scale data analysis infrastructure. This minimizes Total Cost of Ownership (TCO) and allows organizations to focus on critical issues while quickly experimenting with AI development. dotData Cloud’s architecture, certified as an AWS "Competency Partner," ensures top-tier technology standards and uses a single-tenant model for enhanced data security.